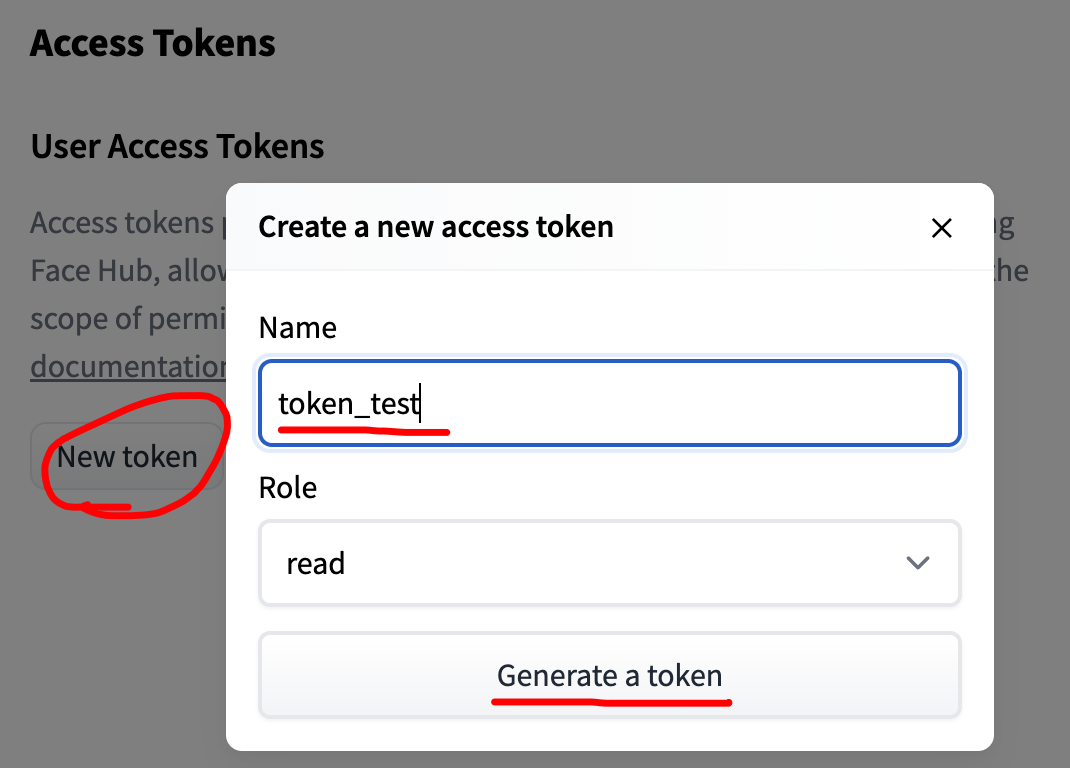
face_recognition 顔画像認識
以前から、opencvを使用した顔の判定プログラムを作ったことはありましたが、今回は、pythonライブラリである「face_recognition」を使用して、事前収集した画像データを基に、個人を識別するプログラムに挑戦しましたので、ご紹介します。

face_recognitionについて
face_recognitionは、著名な顔認識ライブラリである「dlib」(C++)を、pythonで簡易的に使用するために開発されたライブラリです。顔画像に特化したメソッドが豊富に用意されており、CNNを使用した顔の識別、近似値を使用した顔の比較、顔の部分取得(目・鼻・口・輪郭など)を行うことができます。

opencvとface_recognition
大雑把にいうと、opencvよりも、face_recognition(dlib)の方が、より精密な顔識別が可能です。ただ、精度が高い分、検出速度とはトレードオフの関係にあり、face_recognition、特にCNN方式で顔画像を識別しようとした場合、GPUのサポートがないと、1枚の写真から顔を特定するのに数秒~数十秒の時間を要します。
他方、opencvの顔画像検出では、デモンストレーションデータとしてライブラリとともに提供される「haarcascade_frontalface_alt.xml」が用いられます。これは「Haarアルゴリズム」という画像の特徴量を算出する方法を用いた分類データですが、あくまで「frontal(正面)」の顔識別用であるため、顔を傾けたり、少し横を向いただけで顔が判別できなくなります。
2つの詳細な差分については、次のサイトが非常に参考になりました。
サンプルプログラム
今回作成したプログラムは、予め収集した顔画像データとの比較を、次の2つのモードで実現する機能を持っています。
ファイル検出モード(静止画)
入力された画像イメージ(集合写真など)から、顔画像を検出し、それが誰なのかを識別します。

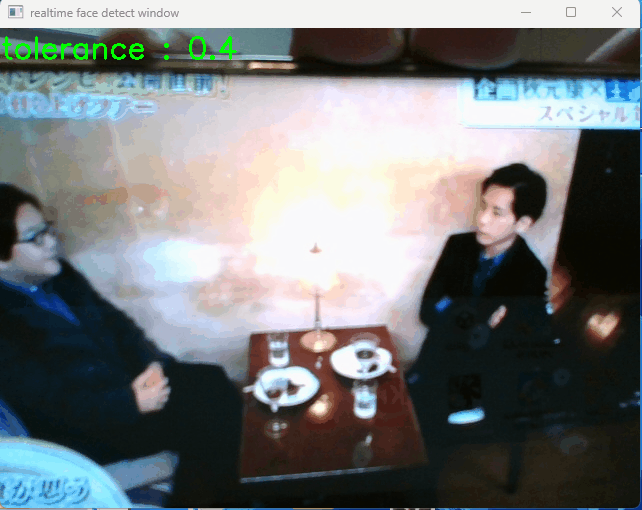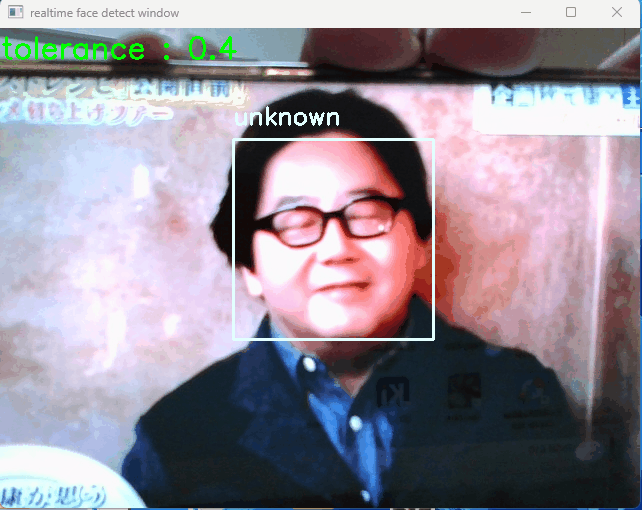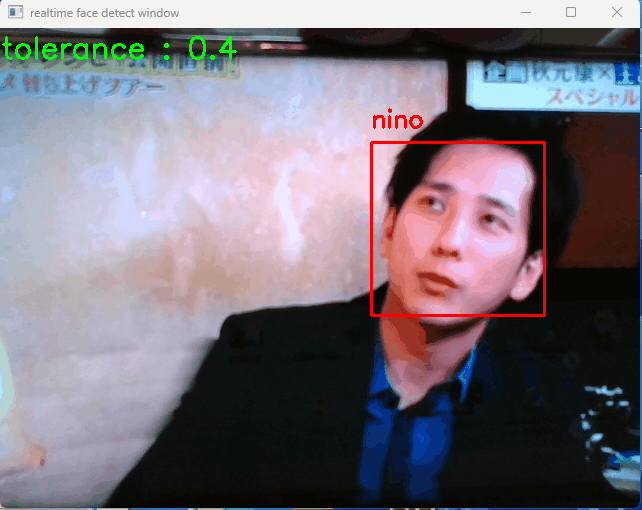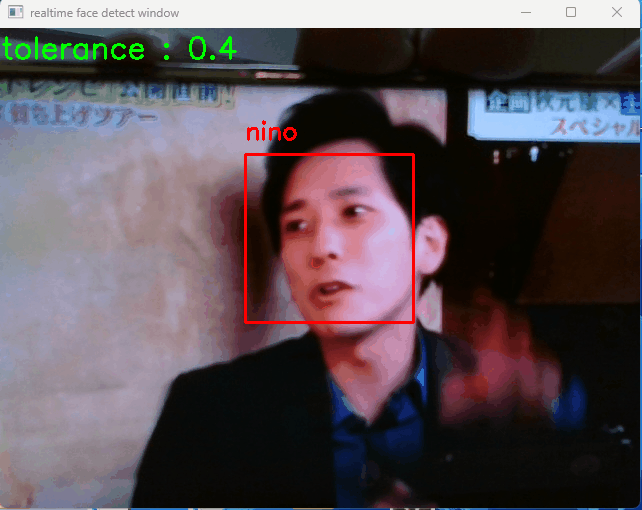
カメラ検出モード(動画)
デバイスのカメラを起動し、カメラ動画に移る人を識別して名前を表示します(自分の顔を映すのがイヤだったので、下の動画はカメラの先で動画再生をしています…)
なお、画像の収集も自動で行えるよう、複数のWebサイトを巡回して画像を集めてくるプログラムも提供しています(01_get_model_data.py)
使用環境・主なライブラリ
プログラム解説
01.データ収集
以下のコマンドを実行すると、入力欄が表示されるので、検索ワード、人物ラベル(半角英字)、取得画像枚数を指定する。
python 01_get_model_data.py
./model_rawdataディレクトリに、人物ラベルのディレクトリが作られ、取得した画像が格納される。
02.顔画像切り出し
収集した画像から特徴が明確になるように、顔部分だけを取り出した画像を作成する。
以下のコマンドを実行すると、
./model_rawdataディレクトリ内のすべての画像に対して、自動でトリミングが行われる。python 02_triming_face.py
./model_datasetディレクトリに、人物ラベルのディレクトリが作られ、トリミングした結果が格納される。
03.モデルデータの水増し
深層学習の精度を高めるため、顔画像に以下の加工を施してデータを増産(水増し)する。
+30° 傾ける
-30° 傾ける
灰色にする
左右対称とする
以下のコマンドを実行することで、
./model_rawdataディレクトリ内のすべての画像に対して、上記の加工が自動で行われる。./model_datasetディレクトリに、上記の加工を行った画像が追加される。
04.モデル学習
以下のコマンドでモデルデータを作成する。
python 04_train_model.py
実行するにはかなりの負荷がかかるため、以下いずれかの環境を推奨する。
正常に終了した場合は、モデルデータ
encodings.pickleファイルが作成される。
05.検出テスト
ファイル検出モード(静止画)
以下のコマンドを実行すると、画像からモデルデータ作成した対象者の顔検出を実行する。
python 05_detect_face.py [検出対象の画像ファイル]
検出した結果は、ディレクトリ「photo_detected」に格納される。検出用の jpg 画像の中で、顔と識別された箇所には黄色い □ 枠が表示され、モデルデータと一致した場合波枠の上部にモデル名が表示される。

カメラ検出モード(動画)
以下のコマンドを実行すると、PC に接続しているカメラ動画から、モデルデータとして作成した対象者の検出を実行する。
python 05_detect_face.py
カメラの動画がウィンドウ背面に出る場合があります。
プログラムを止めるには、ウィンドウ上で「q」キーを押下してください。
ウインドウで「+」「-」キーを押すと「tolerance」値を変更することができ、識別精度が変わります(小さい方がシビアに識別します)
今後の課題
カメラ検出モードだと、画像がカクつく。
やはり、CUDAモジュール搭載のGPUがないと、動画にするのは厳しいことが判明しています。年末ボーナスを受けて、Jetson nanoを購入したので、環境が整ったら、そちらでリトライしてみようと思います。
強化学習への進化
今回の識別(顔の比較)は、face_recognitionのメソッドを使用しており、比較方法も集積画像の数値による「パターンマッチング」でしかない認識です。今後、深層学習によるモデルの作成と比較を学び、自力での画像比較を行っていきたいと考えています。