Claude Code × MCPで実現した、40件超のOracle接続コード自動変換
はじめに
本記事では、VBA/VB6のOracle接続方式をOO4O(Oracle Objects for OLE)からOLEDB(ADODBプロバイダー)に変換するプロジェクトについて紹介します。Claude CodeとMCP(Model Context Protocol)を活用し、1か月で41件のプロジェクト変換を実現しました。
通常であれば7人月以上かかる約6,800行の改修を、わずか0.75人月で完了。IPA基準比で約90%の工数削減、生産性は約19倍を達成しました。
第1章:背景と課題
OO4O(Oracle Objects for OLE)とは
OO4Oは、VBAやVB6からOracleデータベースに接続するためのCOMコンポーネントです。1990年代後半から2000年代にかけて、Excel VBAやVB6アプリケーションでOracle接続を行う際の標準的な手法として広く使われてきました。
' OO4Oによる接続例
Dim OraSession As OraSession
Dim OraDatabase As OraDatabase
Set OraSession = CreateObject("OracleInProcServer.XOraSession")
Set OraDatabase = OraSession.OpenDatabase("ORCL", "user/pass", 0)
OO4Oサポート終了の影響
Oracleは既にOO4Oのサポートを終了しており、新しいOracle Clientには同梱されなくなっています。これにより、以下の問題が発生します:
- 新しい環境でOO4Oを使用したアプリケーションが動作しない
- セキュリティパッチが提供されない
- 64bit環境での制約
手作業での変換が現実的でない理由
今回の対応では、OO4Oを使用したExcel VBAツールが多数存在していました。これらを手作業で変換しようとすると:
| 課題 | 詳細 |
|---|---|
| コード量 | 1ファイルあたり数百〜数千行、全体で数万行 |
| 変換パターンの複雑さ | DB接続、RecordSet、トランザクション、ストアドプロシージャ等、多岐にわたる |
| 型変換の罠 | OO4OとADODBでNUMBER型の返却値が異なる(後述) |
これを人手で行うのは現実的ではありませんでした。
第2章:プロジェクトの大前提 ― すべてバイブコーディング
変換システム自体もAIに作らせた
本プロジェクトの最大の特徴は、変換システム自体をAIに作らせたことです。いわゆる「バイブコーディング」で、以下のすべてをClaude Codeに生成させました:
| 成果物 | 説明 |
|---|---|
| MCPサーバー(excel-pywin32) | Excel VBAファイルの読み書き、参照設定変更 |
| MCPサーバー(oracle-metadata) | Oracleのテーブル/プロシージャ定義検索 |
| エージェント定義ファイル(CLAUDE.md) | フェーズ管理、変換ルールの定義 |
| サブエージェントファイル | oracle-analyze, oracle-convert, oracle-comment等 |
| チェックロジック | 各フェーズの品質検証 |
| レポートテンプレート | 分析結果、変換結果のレポート形式 |
| 自動テストコード | MCPツールの動作確認テスト |
人間がやったこと
人間の役割は限定的でした:
最初の変換指示を出す
- 「このExcelファイルのOO4OをOLEDBに変換して」
各工程の成果物をチェック・承認する
- WinMergeで3点比較:変更前 / 変更後 / インポート後再エクスポート
- 意図しない変更がないか確認
入れ子構造
バイブコーディングで「開発ツールを開発する」という入れ子構造が生まれました:
人間 → 要件を言語化 ↓ AI → MCPサーバーを生成 AI → エージェント定義を生成 AI → テストコードを生成・実行 ↓ AI → 生成したツールを使って変換を実行 ↓ 人間 → 成果物をレビュー・承認
AIが作ったツールをAIがテストし、AIが使う。人間は指示と承認のみ。
第3章:解決アプローチ
Claude Code + MCPという選択
変換システムの実装にあたり、Claude CodeとMCP(Model Context Protocol)の組み合わせを選択しました。
Claude Codeを選んだ理由:
- 自然言語での指示が可能
- コードの文脈理解力が高い
- 複雑な変換パターンを柔軟に処理できる
MCPを選んだ理由(当時の判断):
- Claude Codeから外部ツールを呼び出す標準的な方法
- Excel操作やDB定義検索を独立したサーバーとして実装可能
- ツールの再利用性
従来のコンバートプログラムとAI活用の違い
この手の変換作業では、正規表現ベースのコンバートプログラムを自作するアプローチがよく取られます。しかし、ルールベースの変換には限界があります。
従来のコンバートプログラムの課題:
- 事前に想定したパターンしか変換できない
- 変換もチェックも同じルールベースなので、ルールから漏れたものは検出できない
- 新しいパターンに遭遇するたびにルールを追加する必要がある
AI活用のメリット:
- 文脈を理解して柔軟に変換できる(コメント内か実コードかの判断など)
- 事前に想定していないパターンにも、それなりに対応できる
- 変数のスコープや使われ方を見て、適切な変換を判断できる
本システムでは、このAIのファジーさを活かしつつ、チェックフェーズではMCPツールによる厳格なルールベース検証を行います。
| フェーズ | 実行主体 | アプローチ |
|---|---|---|
| 変換 | AI | ファジー:文脈を理解して柔軟に変換 |
| チェック | MCPツール | 厳格:ルールベースで網羅的に検出 |
AIが見落としてもチェックツールが拾い、チェックルールにないパターンでもAIが対応する。この相互補完により、変換漏れのリスクを低減しています。
注意点:ファジーさゆえのデメリット
AIにファジーな変換を依頼しているため、コードの完全再現性がないというデメリットがあります。例えば、同じソースがコピペされた複数のExcelを変換した場合、Excelごとに異なる変数名が付けられることがあります。構造的には問題がないため、チェックには引っかかりません。
本アプローチは、このような差異が許容されることが前提です。変換後のコードが完全に同一であることを求める場合は、従来のルールベース変換の方が適しています。
半自動化という設計思想
完全自動化ではなく、半自動化を採用しました:
- 分析結果はユーザーが確認・承認してから変換に進む
- 変換結果もユーザーが確認・承認してからインポート
- 各工程でチェックフェーズを設け、問題があれば再実行
これにより、AIの暴走を防ぎつつ、人間の負担を最小化しています。
第4章:システムアーキテクチャ
全体構成
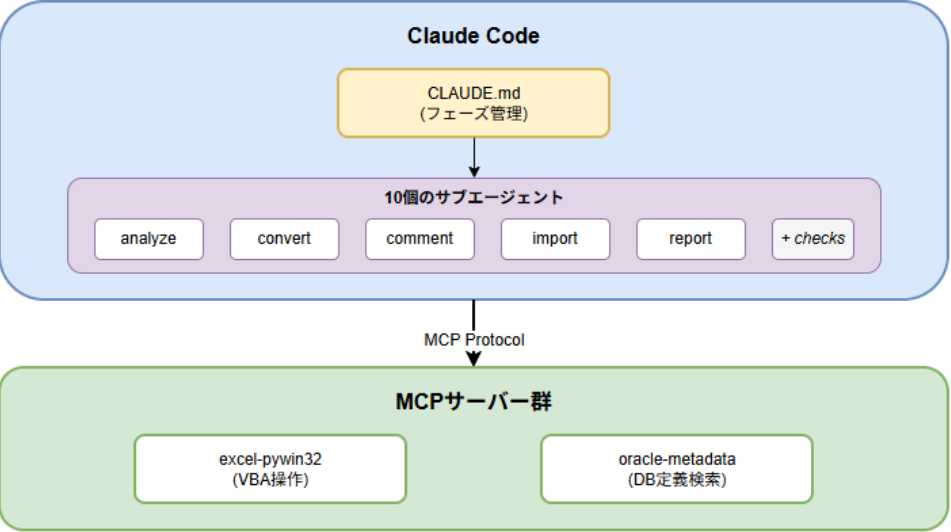
システムは3層構造になっています:
Claude Code(最上位)
- CLAUDE.md(フェーズ管理ファイル)を読み込み、全体を制御
10個のサブエージェント
- analyze, convert, comment, import, report(各作業フェーズ)
- 各フェーズに対応するcheckエージェント
MCPサーバー群
5フェーズ × チェックの品質管理モデル
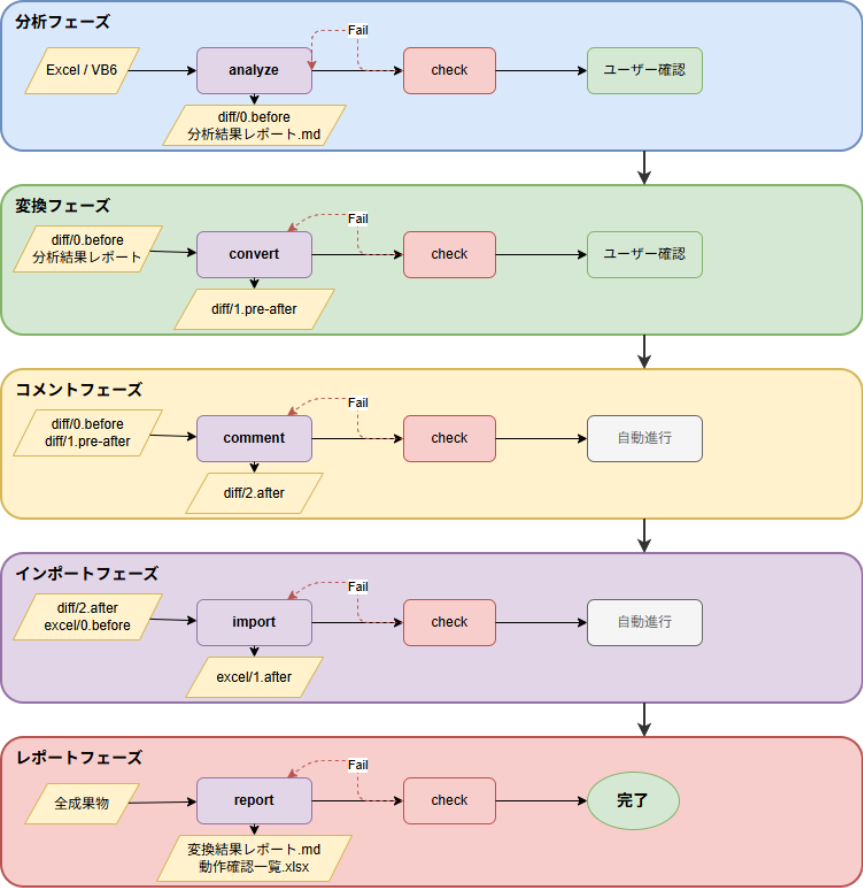
| フェーズ | 処理内容 | 出力 |
|---|---|---|
| 分析(analyze) | OO4O使用箇所の特定、変換計画作成 | diff/0.before/, 分析結果レポート.md |
| 変換(convert) | 変換計画に従ってコード変換 | diff/1.pre-after/ |
| コメント(comment) | OCI対応コメントの付与 | diff/2.after/ |
| インポート(import) | Excelへのインポート、参照設定変更 | excel/1.after/ |
| レポート(report) | 変換結果レポート、動作確認一覧作成 | 変換結果レポート.md, 動作確認一覧.xlsx |
各フェーズの後にはチェックフェーズがあり、Failの場合は作業フェーズを再実行します。
MCPサーバーの役割
excel-pywin32サーバー:
project_export_full → VBAモジュールをエクスポート project_import_converted → 変換後モジュールをインポート vba_file_read → VBAファイル読み込み(Shift-JIS対応) vba_file_edit → パターン置換 vba_add_oci_comments → OCI対応コメント自動付与 vba_add_reference → 参照設定追加(ADODB等) vba_remove_reference → 参照設定削除(OO4O等)
oracle-metadataサーバー:
search_procedure_params → ストアドプロシージャのパラメータ検索 search_table_columns → テーブルのカラム定義検索
第5章:変換パターンの技術詳細
DB接続・切断の変換
' 変換前(OO4O)
Dim OraSession As OraSession
Dim OraDatabase As OraDatabase
Set OraSession = CreateObject("OracleInProcServer.XOraSession")
Set OraDatabase = OraSession.OpenDatabase("ORCL", "user/pass", 0)
' 変換後(OLEDB)
Dim OraConnection As ADODB.Connection
Set OraConnection = New ADODB.Connection
OraConnection.Open "Provider=OraOLEDB.Oracle;" & _
"Data Source=ORCL;" & _
"User ID=user;Password=pass"
OO4OではOraSessionとOraDatabaseの2オブジェクトが必要でしたが、OLEDBではADODB.Connection1つに統合されます。
Recordset(CreateDynaset → Rs.Open)
' 変換前(OO4O) Dim Rs As OraDynaset Set Rs = OraDatabase.CreateDynaset(strSql, 0) ' 変換後(OLEDB) Dim Rs As ADODB.Recordset Set Rs = New ADODB.Recordset Rs.Open strSql, OraConnection, adOpenStatic, adLockReadOnly
トランザクション処理
' 変換前(OO4O) OraSession.BeginTrans OraSession.CommitTrans OraSession.Rollback ' 変換後(OLEDB) OraConnection.BeginTrans OraConnection.CommitTrans OraConnection.RollbackTrans ' 注:Rollback → RollbackTrans
ストアドプロシージャ
OO4OとOLEDBのパラメータ指定方式の違い
OO4OとOLEDBでは、ストアドプロシージャのパラメータ指定方式に重要な違いがあります。
| 方式 | OO4O | OLEDB/ADODB |
|---|---|---|
| パラメータ指定 | 名前指定が可能 | 位置指定のみ |
| パラメータ順序 | 順不同でOK | 定義順に厳密に合わせる必要あり |
OO4Oでは :パラメータ名 で名前を指定できましたが、ADODBのOLE DBプロバイダーでは、パラメータは位置(ordinal)で識別されます。つまり、Parameters.Append する順序がストアドプロシージャの定義順と完全に一致している必要があります。
参考: ADO Command object ignores parameter names when invoking stored procedure - ADOのドキュメントでは、パラメータの "name" プロパティはVBプログラム内でパラメータを識別するためだけのものであり、ストアドプロシージャのパラメータとは位置(ordinal)でのみ対応すると記載されています。
参考: Microsoft Learn - Using Parameters (OLE DB)) - OLE DBではパラメータは名前付きでも無名でも、常にordinalで識別されます。
この違いにより、変換時にはoracle-metadataサーバーを使ってパラメータの定義順序を正確に取得し、その順序通りにパラメータを追加する必要がありました。
変換例
' 変換前(OO4O)- 名前指定でパラメータを追加
OraDatabase.Parameters.Add "p_name", "", 2 ' 2番目のパラメータを先に追加してもOK
OraDatabase.Parameters.Add "p_id", 100, 1 ' 1番目のパラメータを後から追加
OraDatabase.ExecuteSQL "BEGIN pkg.proc(:p_id, :p_name); END;"
result = OraDatabase.Parameters("p_name").Value
' 変換後(OLEDB)- 定義順にパラメータを追加(順序が重要!)
Dim Cmd As ADODB.Command
Set Cmd = New ADODB.Command
Cmd.ActiveConnection = OraConnection
Cmd.CommandText = "pkg.proc"
Cmd.CommandType = adCmdStoredProc
Cmd.Parameters.Append Cmd.CreateParameter("p_id", adInteger, adParamInput, , 100) ' 1番目
Cmd.Parameters.Append Cmd.CreateParameter("p_name", adVarChar, adParamOutput, 100) ' 2番目
Cmd.Execute
result = Cmd.Parameters("p_name").Value
型変換の落とし穴(NUMBER型のDecimal/String問題)
これが最も厄介な問題でした。OO4OとADODBでは、Oracle NUMBER型の値取得時に返却されるVBAのデータ型が異なります。
| 技術 | NUMBER型の返却 |
|---|---|
| OO4O | 精度16桁以上 or 精度未指定 → String |
| ADODB | すべて → Decimal |
この違いにより、既存コードが暗黙的にString型を期待している場合、変換後に実行時エラーが発生します。
対策: convertType() 関数を全Recordsetフィールドアクセスに適用し、OO4Oと同じ挙動を再現するモジュールを追加しました。
第6章:工夫したポイント
AIモデルの使い分けとエージェント分離
当初の問題
当初は、1つのCLAUDE.mdファイルにすべてのプロセス(分析→変換→コメント付与→インポート→レポート)を記述していました。しかし、以下の問題が頻発しました:
- 作業の一部を漏らす: 長い指示の中で特定のステップをスキップしてしまう
- ユーザー確認をせずに勝手に進める: 確認ポイントを無視して次のフェーズに突入
- 指示の解釈ブレ: 同じ指示でも実行のたびに異なる挙動
原因の推測
- コンテキストの肥大化: 1つのファイルに全情報を詰め込むと、AIが重要な指示を見落としやすくなる
- 責任範囲の曖昧さ: 「何をどこまでやるか」が不明確だと、AIが勝手に判断してしまう
- チェックポイントの欠如: 途中で品質確認する仕組みがないと、エラーが連鎖する
対策:メインエージェント + サブエージェント構成
この問題への対策として、以下の設計に変更しました:
| 層 | 役割 | 内容 |
|---|---|---|
| メインエージェント(CLAUDE.md) | フェーズ管理のみ | 次にどのサブエージェントを呼ぶか判断、ユーザー確認ポイントの制御 |
| サブエージェント(oracle-*.md) | 作業の実行 | 1つのフェーズに集中、明確な入力/出力定義 |
| チェックエージェント(*-check.md) | 品質ゲート | 作業結果の検証、Pass/Fail判定 |
モデルの使い分け
処理の特性に応じてAIモデルも使い分けています:
| フェーズ | モデル | 理由 |
|---|---|---|
| analyze, report, check系 | デフォルト(高精度) | 分析・判断の精度が重要 |
| convert, comment, import | sonnet(高速) | 定型処理が多く、速度優先 |
チェックフェーズによる品質ゲート
各作業フェーズの後にチェックフェーズを設け、以下を自動検証します:
- OO4Oコードの残存チェック
- 改行コードの異常(CRLF以外の混入)
- 構文エラーの検出
- インポート前後の差分確認
Failの場合は問題箇所を特定し、作業フェーズを再実行します。
3段階のdiff比較による品質担保
成果物は3段階で保存され、WinMergeで比較確認できます:
diff/0.before/ ← 変換前のオリジナル diff/2.after/ ← 変換・コメント付与後 diff/3.exported_for_check/ ← Excelにインポート後、再エクスポートした結果
インポート→再エクスポートで差異が出れば、インポート処理に問題があることがわかります。
DBメタデータ活用
ストアドプロシージャの変換では、oracle-metadataサーバーを使ってパラメータの型情報と定義順序を取得します。これにより、手動でDB定義を調べる必要がなくなり、パラメータ順序の誤りも防げるようになりました。
第7章:苦労話 ― AIは思い通りに動かない
バイブコーディングは万能ではありません。実際に遭遇した問題を紹介します。
例1:MCPツール接続失敗時の暴走
現象: MCPサーバーに接続できない場合、AIは「問題を解決しよう」として、勝手に代替スクリプトを生成し始めました。
# AIが勝手に生成したスクリプト with open(vba_file, 'r', encoding='utf-8') as f: # ← UTF-8で読もうとする content = f.read()
結果: VBAファイルはShift-JIS(CP932)でエンコードされているため、UTF-8で読み込んで書き戻すと文字化けが発生。日本語コメントや文字列リテラルが破壊されました。
対応: CLAUDE.mdに「MCPツールが使えない場合は処理を中断し、ユーザーに報告すること」と明記しましたが、どんなに指示を加筆してもAIが暴走することはたまにありました。
結局、CLI上で作業フェーズを常に監視し、AIが想定外の行動(独自スクリプトの生成等)を始めたらEscキーで即座に中断してやり直しさせる運用で対処しています。完全な解決には至っていません。
例2:並行セッションによるソース破壊
現象: 作業効率を上げるため、複数のClaude Codeセッションで並行作業させていました。
結果: 同一ファイルを複数セッションが同時に編集し、あるセッションの変換済みコードを別のセッションが上書き・破壊。変換作業が無駄になりました。
対応: AIには排他制御の概念がありません。以下の運用ルールで対処しました:
- プロジェクト範囲を明示する: 本来の作業フェーズと異なる指示を出す場合も「〇〇プロジェクトの範囲で」を枕詞として必ず付ける
- バックアップ指示の明示: ケースによっては「バックアップを取ってから作業すること」と明確に指示
- 並行作業は完全分離: 同時に作業させる場合はプロジェクト単位で完全に分離
例3:指示無視と過剰な「改善」
現象: 変換作業を指示したにもかかわらず、AIが「ついでに」コードの改善を行いました:
- 未使用変数の削除
- インデントの修正
- 変数名のリネーム
結果: OO4O→OLEDB変換とは無関係な変更が混入し、動作確認時に「何が変わったのか」の切り分けが困難に。最悪の場合、意図しない動作変更が発生しました。
対応: 禁止事項を明文化し、繰り返し指示する必要があります。CLAUDE.mdに以下を追記:
## 禁止事項 - OO4O変換と関係ない変更を行うこと - 未使用変数の削除、リファクタリング等の「改善」 - コメントの追加・削除(OCI対応コメント以外)
第8章:実績と効果
変換実績
1か月の作業期間で、41件のプロジェクト変換を完了しました。作業者は1名(約0.75人月稼働)、総修正規模は約6,800ステップです。
IPA基準との比較
IPA(独立行政法人 情報処理推進機構)の「ソフトウェア開発分析データ集2022」に基づき、生産性を比較しました。
IPA基準値
IPAが公開している改良開発の生産性基準値は以下の通りです:
| 生産性(中央値) | 人月換算(160人時) | |
|---|---|---|
| 改良開発 | 3.01 SLOC/人時 | 約482 SLOC/人月 |
工程範囲
今回の作業範囲は、実装とコンパイルの確認までを実施しました。変換結果のテストはサンプリングで動作確認を行い、各Excelファイルごとの単体テストや結合テスト以降は実施していません。
IPA基準の開発工程に当てはめると、基本設計・詳細設計・製造(実装)の52%に該当します。
| 基本設計 | 詳細設計 | 製造(実装) | 製造(単体) | 結合テスト | 総合テスト | 合計 | |
|---|---|---|---|---|---|---|---|
| IPA基準 | 18% | 18% | 16% | 15% | 20% | 13% | 100% |
| 本PJ | ✓ | ✓ | ✓ | - | - | - | 52% |
IPA基準での工数試算
| 計算式 | 値 | |
|---|---|---|
| 総ステップ数 | - | 約6,800行 |
| IPA基準工数(全工程) | 6,800 ÷ 482 SLOC/人月 | 約14人月 |
| IPA基準工数(実施工程52%) | 14 × 52% | 約7人月 |
実績との比較
| IPA基準 | 実績 | 比較 | |
|---|---|---|---|
| 工数(実施工程) | 約7人月 | 0.75人月 | 約90%削減 |
| 生産性 | 482 SLOC/人月 | 約9,100 SLOC/人月 | 約19倍 |
AI支援(Claude Code + サブエージェント)により、IPA基準比で約90%の工数削減を実現しました。
第9章:振り返り ― MCPである必要はあったのか?
結論:MCPでなくてもよかった
正直に言うと、MCPは過剰だったかもしれません。
代替案1:単純なPythonスクリプト
excel-pywin32サーバーの機能は、単純なPythonスクリプトでも実現可能でした:
# これでも十分だった def export_vba_modules(excel_path, output_dir): xl = win32com.client.Dispatch("Excel.Application") wb = xl.Workbooks.Open(excel_path) for component in wb.VBProject.VBComponents: component.Export(f"{output_dir}/{component.Name}.bas") wb.Close() xl.Quit()
Claude Codeはbashやpythonスクリプトを直接実行できるので、MCPサーバーという形式にする必要はありませんでした。
代替案2:Claude Skills(カスタムスキル)
Claude Codeには「Skills」という機能があり、よく使う処理をスキルとして定義できます。MCPサーバーを立てるよりシンプルです。
MCPを選んだ理由(当時の判断)
- MCPが新しい技術で試してみたかった
- 「サーバー」という形式にすることで再利用性が高まると考えた
- 複数のClaude Codeセッションから共有できると思った
MCPを使ったことで被った問題
実際に運用してみると、MCPサーバーへの接続が頻繁に切れるという問題が発生しました。
- 作業中に突然MCPツールが使えなくなる
/mcpコマンドで再接続を試みる必要がある- 再接続しても不安定な場合があり、Claude Codeの再起動が必要になることも
原因は完全には特定できていませんが、以下が考えられます: - MCPサーバープロセスのタイムアウト - Windowsの環境依存の問題 - 長時間稼働による接続の不安定化
この問題により作業が中断されることが多く、シンプルなスクリプト実行の方が安定していた可能性があります。
今振り返っての評価
| 観点 | 評価 |
|---|---|
| 学習コスト | MCPサーバーの実装・デバッグに時間がかかった |
| 安定性 | サーバー接続問題で作業中断が頻発 |
| 再利用性 | 結局このプロジェクト専用になった |
| 代替手段 | スクリプトやSkillsで十分だった |
MCPが活きるケース vs 過剰なケース
MCPが活きるケース:
- 複数のAIツール(Claude, GPT等)から共通して使いたい
- 長時間稼働するサービスとして提供したい
- 複雑な状態管理が必要
過剰なケース(今回のような):
- 単一のClaude Codeセッションで完結する
- バッチ的な処理で、常駐サーバーは不要
- プロジェクト固有の処理で再利用予定がない
第10章:今後の展望・まとめ
他のレガシーコード変換への応用可能性
今回のアプローチは、他のレガシーコード変換にも応用できます:
フェーズ管理とチェック機構の考え方は汎用的に使えます。
バイブコーディングで学んだこと
AIは万能ではない
- 思い通りに動かないことが多い
- 禁止事項の明文化と繰り返しの指示が必要
- 暴走したらEscで止めてやり直し
人間の役割は「指示と承認」
シンプルな選択が正解のこともある
- 新しい技術(MCP)に飛びつく前に、既存の手段で十分か検討すべき
- 安定性 > 新しさ
まとめ
1か月で41件のOO4O→OLEDB変換を、Claude Code + MCPで実現しました。
- バイブコーディングで変換システム自体をAIに作らせた
- フェーズ管理とチェック機構で品質を担保
- IPA基準比で約90%の工数削減、生産性18.9倍を達成
- 苦労もあったが、手作業に比べて大幅な効率化を達成
- MCPは過剰だったかもしれないが、学びは多かった
レガシーコードの移行に悩んでいる方の参考になれば幸いです。
参考文献
- IPA ソフトウェア開発分析データ集2022
- ADO Command object ignores parameter names - Google Groups
- Microsoft Learn - Using Parameters (OLE DB))
- ADODB.Command and Parameter order - Tek-Tips
本記事の執筆にあたり、実際のプロジェクトで使用したCLAUDE.md、エージェント定義、MCPサーバーのコードを参考にしました。
ECS WebサービスのCICDパイプライン構築(CloudFormation)
AWSで、S3のフロントとECS Fargateをバックエンドを組み合わせサーバレスWebシステムと、それをCI/CD駆動させる環境を、CloudFormationで構築しました。 以下に構成全体の説明と、構築までの流れ・ポイントについてご紹介します。
システム概要
システム構成
構成図
システム全体の構成を下図に示します。

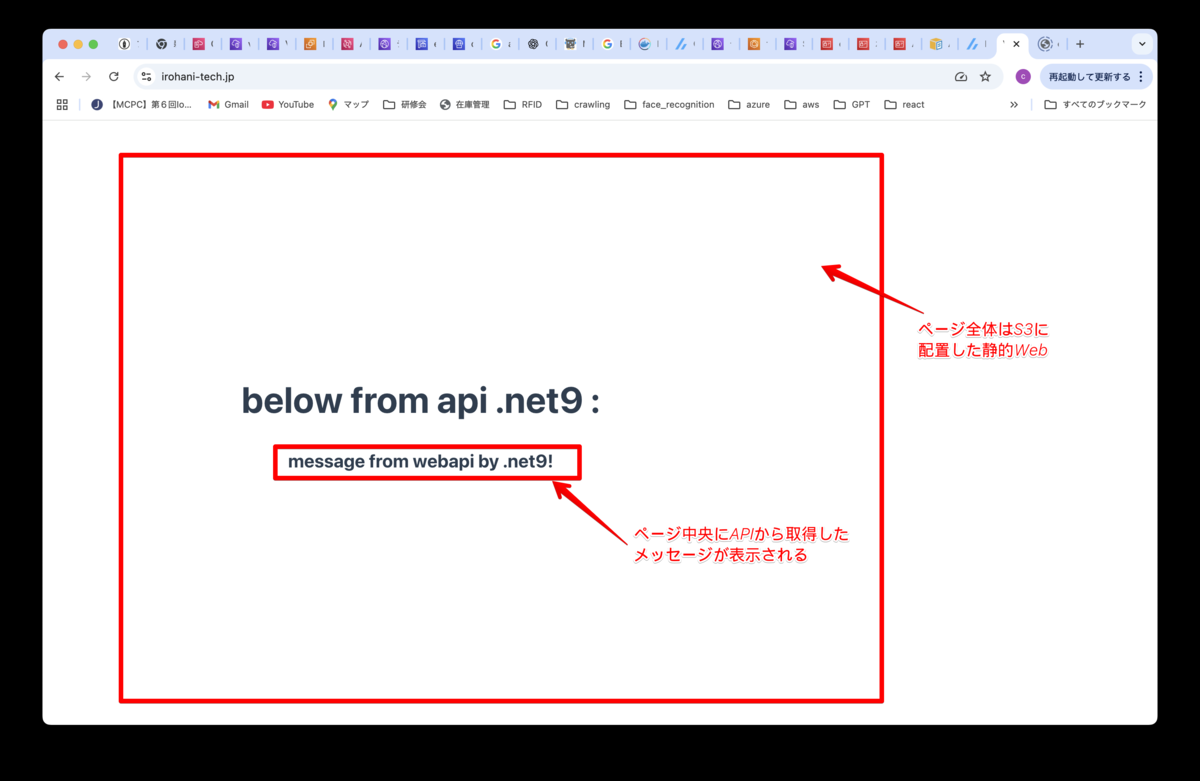
構築するアプリケーション
アプリケーションはシンプルで、S3バケットに置いた静的サイトの中央に、WebAPIから取得したメッセージを表示するものです。
ポイント
フロント構成は、S3の静的Webサイトホスティングで公開します。
バックエンド構成は、ECS Fargateで稼働しています。
上記2つのソース(Vue.js、.net WebAPI)に対し、GitHubを起点としたCI/CDパイプラインを実装しています。
- GitHubにプッシュしたソースは、ActionsがS3にアップロードします。
- S3へのアップロードをEventBridgeが検知し、パイプライン(Code Pipepline)を起動します。
- Pipelineがそれぞれのビルドを行い、稼働先のプラットフォームをアップデートします。
リソース
本システムのリソースは、以下のGitHubリポジトリにて公開しています。 github.com
事前準備
前提条件
本システムと同環境を構築するには、次のことが事前に必要となります。
以下のアプリケーションをローカル環境にセットアップしてください。
- Docker
- Node.js
- Vue.js
- .net core 9
- 独自ドメインを取得し、Route53のホストゾーンとして登録済みであること。
- ACMで、Route53登録済みドメインの証明書を作成済みであること。
- GitHubアカウントを取得しており、アカウントにWorkflow使用権限が付加されていること(GitHub Actions)
GitHubからリソースを取得
前述のGitHubを自身のアカウントにフォークした後、ローカル環境にCloneしてください。
git clone <Gitリポジトリアドレス>
パラメタファイルの作成
Cloneした環境のcfnディレクトリ配下に、parametersディレクトリを作成し、その下に次のファイルを作成してください。[ ]には、事前準備で用意した内容を設定してください。
1. parameter_cdn.json
[
{"ParameterKey": "CustomDomainName", "ParameterValue": "[サイトを公開する独自ドメインアドレス]"},
{"ParameterKey": "Route53HostZoneId", "ParameterValue": "[Route53のホストゾーンID]"},
{"ParameterKey": "AcmCertificateArn", "ParameterValue": "[発行した証明書のArn]"}
]
- アドレスの設定例「www.xxxxxxxx.jp」
- ホストゾーンIDは、AWSマネジメントコンソールの、Route53の詳細画面に表示されています。

2. parameter_oidc.json
[
{"ParameterKey": "GitRepository", "ParameterValue": "[GitHubのレポジトリ]"}
]
レポジトリは、「アカウント名/レポジトリ名」の形式で設定してください。例「camelrush/aws_ecs_cicd」。
構築手順
以下に、環境構築の手順をご紹介します。
ECRレポジトリ作成とイメージプッシュ
最初に、WebAPIを構成するためのECRリポジトリを作成し、イメージを登録しておきます。
ちょっと順番があべこべですが、バックエンドのCFnをスムーズに進めるため、先に入れておきます。

ローカル環境から、以下のコマンドを実行してください。
# CloudFormation ディレクトリへ移動 cd cfn # cloudformationでECRを作成 aws cloudformation create-stack --stack-name ecscicd-ecr \ --template-body file://template/0.ecr.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1
これにより、ECRレポジトリが作成されますので、AWSマネジメントコンソールで確認します。
 上図のURIをコピーしてください。次の手順で使用します。
上図のURIをコピーしてください。次の手順で使用します。
次に、Dockerでコンテナイメージをビルドします。次のコマンドを実行してください。
# backendソースのディレクトリに移動 cd ../src/backend # ECRレポジトリへのログイン ECR_REPOSITORY_URI=[上記でコピーしたURI] AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) AWS_REGION=ap-northeast-1 aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin ${ECR_REPOSITORY_URI} # コンテナビルド docker build -t api-image:latest . docker tag api-image:latest ${ECR_REPOSITORY_URI}:latest IMAGE_TAG="first" docker tag api-image:latest ${ECR_REPOSITORY_URI}:${IMAGE_TAG}
Dockerが起動し、イメージのビルドが行われます。
ビルドが正常終了したら、ECRにビルドしたイメージをプッシュします。
# ECRにイメージをプッシュ docker push ${ECR_REPOSITORY_URI}:latest docker push ${ECR_REPOSITORY_URI}:${IMAGE_TAG}
AWSマネジメントコンソールでECRのレポジトリを見ると、イメージが追加されたことが確認できます。
ネットワーク基盤
バックエンドの基盤となるネットワーク部分を構築します。

ローカル環境から、以下のコマンドを実行してください。
# 1.network aws cloudformation create-stack --stack-name ecscicd-network \ --template-body file://template/1.network.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1
この項は特にコメントはありません。IPアドレスはCFnに直接書き込んでいますので、変更した場合は任意のアドレスに書き換えてください。
バックエンド
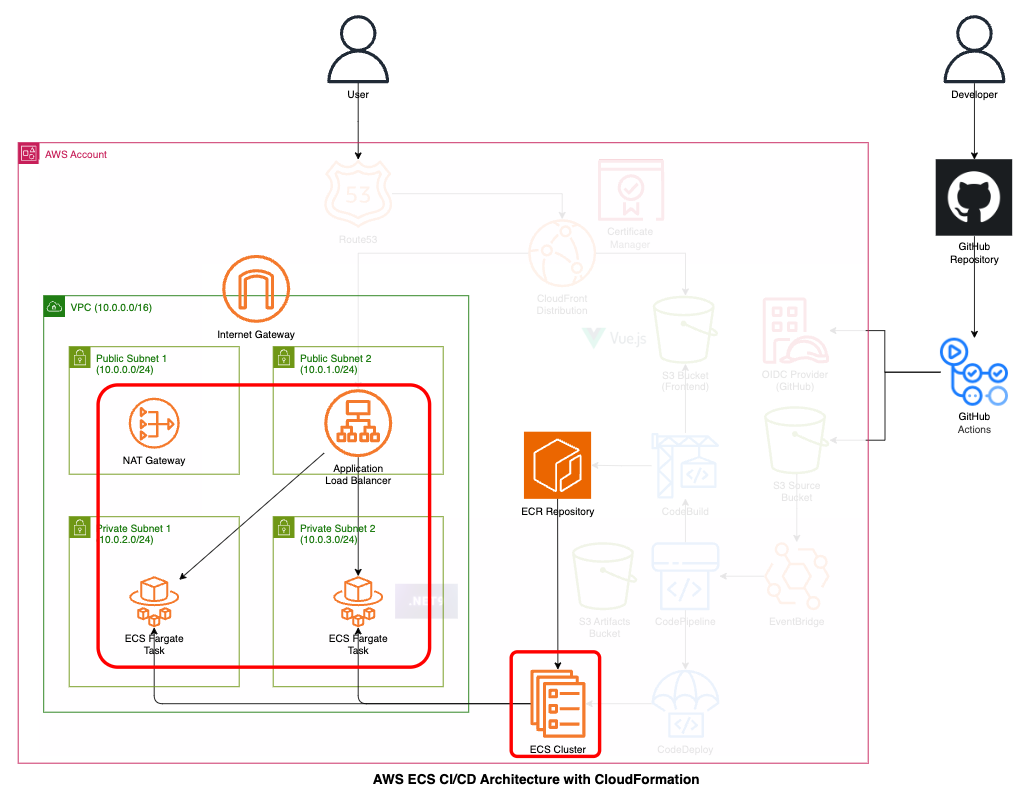
Web APIのインフラ部分であるECS Fargateやロードバランサを配置します。
- ECSクラスター
- ECSサービス
- アプリケーション ロードバランサー
- アプリケーション ターゲットグループ + リスナー(本番系:80ポート)
- アプリケーション ターゲットグループ + リスナー(テスト系:8080ポート)
- ECS用のセキュリティグループ
- ALB用のセキュリティグループ
ローカル環境から、以下のコマンドを実行してください。
# 2.backend aws cloudformation create-stack --stack-name ecscicd-backend \ --template-body file://template/2.backend.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1
このスタックによって、バックエンド向けのALBとECS周りが構成されます。
この構成には、以下のポイントがあります。
テスト系ターゲットグループ
ALBには2つのターゲットグループを設定しており、それぞれ異なるポートでアクセスできるようにしています。
- 本番用ターゲットグループ(80ポート)
- テスト用ターゲットグループ(8080ポート)
8080ポートは普段使いませんが、CodeDeployがBlue/Greenデプロイを行う際に、Green側をテストするのに使用します。Blue/Greenデプロイについては、後述のCI/CDの項で説明します。

ECSの要求数はゼロ
テンプレート内の DesiredCount(要求数)には、ゼロを指定しています。これは、CloudFormationを安全に終わらせるための措置です。

このテンプレートで1以上の値を入れてしまうと、CloudFormationデプロイ中にECSサービスがタスクを起動しようとするのですが、万が一ECSタスクの不良で起動エラーがあると、ECSサービスが起動をリトライさせて、CloudFormationがなかなか終わらなくなります。
CloudFormationが正常終了したことを確認した後、ECSサービスを開き、サービスの更新画面で「必要なタスク」を、0から1以上の値に変更しましょう。問題なければ、指定した数のECSタスクが起動します。

ECS起動確認
backendのタスクが起動したかどうかを確認するため、ブラウザでロードバランサのエンドポイントに接続します。
ブラウザのアドレス欄には、「http://
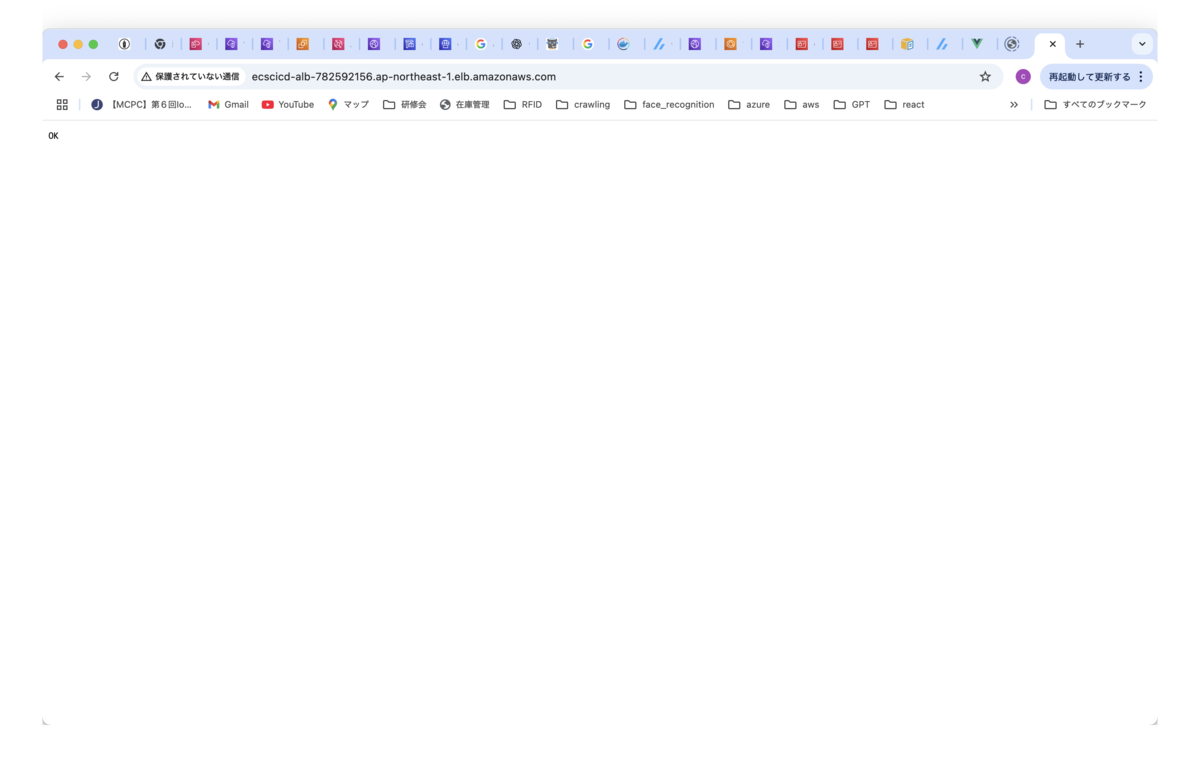
問題なければ、画面内にWebAPIからの応答として、「OK」メッセージが表示されます。
このメッセージは、backend APIのソースでルートアドレスの応答として記述している内容です。

フロントエンド
フロントエンドのWebページを格納するS3バケットを作成します。
- S3バケット

ローカル環境から、以下のコマンドを実行してください。
# 3.frontend aws cloudformation create-stack --stack-name ecscicd-frontend \ --template-body file://template/3.frontend.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1
Webサイトホスティング
フロントエンドのCloudFormationテンプレートでは、WebsiteConfiguration を設定し、静的Webサイトをホストします。
なお、このバケットには次の項で、CloudFrontからのアクセスに限定するバケットポリシーを設定します。

バケットの中身はまだ空です。このバケットへのWebページ格納は、後述のCI/CDパイプラインが行います。
CDN(CloudFront)とHTTPS通信
この項ではCloudFrontを配置して、外部からのアクセス部分を構築します。具体的には、次のことを実施しています。
| 機能 | 説明 |
|---|---|
| CloudFront統合 | S3とALBを1つのCloudFrontでルーティング |
| セキュアなS3アクセス | OACでCloudFrontのみS3にアクセス許可 |
| 独自ドメイン対応 | ACM証明書とRoute53でSSL&独自ドメイン設定 |
| HTTPS対応 | CloudFront経由で全てHTTPSリダイレクト |
- CloudFront ディストリビューション
- オリジンアクセスコントロール(OAC)
- S3バケットポリシー
- Route53 Aレコード(エイリアス名)

ローカル環境から、以下のコマンドを実行してください。
# 4.cdn aws cloudformation create-stack --stack-name ecscicd-cdn \ --template-body file://template/4.cdn.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1 \ --parameters file://parameter/parameter_cdn.json
引数のparameter_cdn.jsonには、本手順冒頭で以下3つが設定済みですので、これらの内容をもとにCDNを構成します。
- CustomDomainName ... サイトを公開する独自ドメインアドレス
- Route53HostZoneId ... Route53のホストゾーンID
- AcmCertificateArn ... 発行した証明書のArn
スタック作成後、CloudFrontにディストリビューションが追加されています。オリジン内容を確認すると、フロントエンドとバックエンドがそれぞれ登録されていることがわかります。

CDN動作確認
カスタムドメイン経由での接続が行えるか、ブラウザでロードバランサのエンドポイントに接続します。
ブラウザのアドレス欄には、「http://<前述の「CustomDomainName」に指定したアドレス>/」を指定します。
問題なければ、冒頭で紹介したWebページの画面が表示されます。
ここまでの手順で、Webサービスが動作するためのインフラリソースは一通り揃った状態です。
CI/CDパイプライン
今度は、WebサービスのCI/CDを構成する各ステップとパイプラインを作成していきます。
- CodeBuild プロジェクト
- CodeDeploy
- CodePipeline
- S3バケット(ソース格納用)
- S3バケット(パイプラインアーティファクト格納用)
- EventBridgeルール

ローカル環境から、以下のコマンドを実行してください。
# 8.pipeline aws cloudformation create-stack --stack-name ecscicd-pipeline \ --template-body file://template/8.pipeline.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1
Code
CodeBuild(ビルドプロジェクト)
CI/CDは、CloudFormationで作られたインフラ構造に加え、buildspec.ymlに定義したステージ動作によって実現します。ここでは、構成ごとのスペックを確認していきます。
フロントエンドのビルド構成
フロント向けのスペックは、ソースの /src/frontend/buildspec.yml に定義しています。
 ここでは、次の流れでフロントページを作成しています。
ここでは、次の流れでフロントページを作成しています。
- ビルドに必要なライブラリのインストール
- ビルド実行
- S3 Bucketにビルド結果をアップロード
- CloudFrontキャッシュの削除
最後にキャッシュを削除することで、ディストリビューションのクリアを行なっています。
バックエンドのビルド構成
バックエンド向けのスペックは、ソースの /src/backend/buildspec.yml に定義しています。

ここでは、次の流れでバックエンドAPIを作成しています。
- ECRにログイン
- Dockerビルド、タグ付け
- ECRにイメージをプッシュ
- CodeDeployに必要なファイルを作成
- taskdef.json
- appspec.yaml
特に、定義の最後の箇所が重要です。
artifacts: files: - imageDetail.json - taskdef.json - appspec.yaml
この記述によって、BuildArtifactに3つの要素を格納し、次のステップ(CodeDeploy)に引き渡しています。
CodeDeploy
CodeDeployでは、バックエンドのCodeBuildで作成したECSタスク定義を使用して、Blue/Greenデプロイを実施します。
ここで使用する appspec.yaml と taskdef.json には、次の内容が記述されています。
taskdef.json
このファイルには、新たに配置するECSタスクの定義情報が設定されています。
{
"family": "${ECS_TASK_FAMILY}",
"executionRoleArn": "arn:aws:iam::${AWS_ACCOUNT_ID}:role/${ECS_EXEC_ROLE_NAME}",
"containerDefinitions": [
{
"name": "${ECS_CONTAINER_NAME}",
"image": "<IMAGE1_NAME>",
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
}
],
"essential": true
}
],
"requiresCompatibilities": [
"FARGATE"
],
"networkMode": "awsvpc",
"cpu": "256",
"memory": "512"
}
imageに指定している<IMAGE1_NAME>は、CodeBuildの最後にアウトプットとして指定したBuildArtifact中の imageDetail.json(Imageタグを記述したJsonファイル)を示しています。
CodePipelineの設定中で、IMAGE1_NAME はプレースホルダーとして定義されています。

appspec.yaml
このファイルでは、デプロイ作業自体を定義しています。使用するタスク定義 TASK_DEFINITION は、前述した taskdef.json が使用されます。
version: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: <TASK_DEFINITION> LoadBalancerInfo: ContainerName: "${ECS_CONTAINER_NAME}" ContainerPort: 80
パイプライン動作確認
上記のスタックで、S3バケットecscicd-source-${AccountId}へのファイル配置をトリガとして、パイプラインを起動するEventBridgeルールが作られています。

ので、デプロイまでの流れを確認します。
次のコマンドで、パイプラインが起動することを確認してください。
# backend/frontendのソースをzip化する cd src zip -r backend.zip backend/ zip -r frontend.zip frontend/ # s3 に ソースをアップロードする aws s3 cp ./backend.zip s3://(バケット名)/src/
フロントエンドのパイプラインは、比較的すぐに終了します。
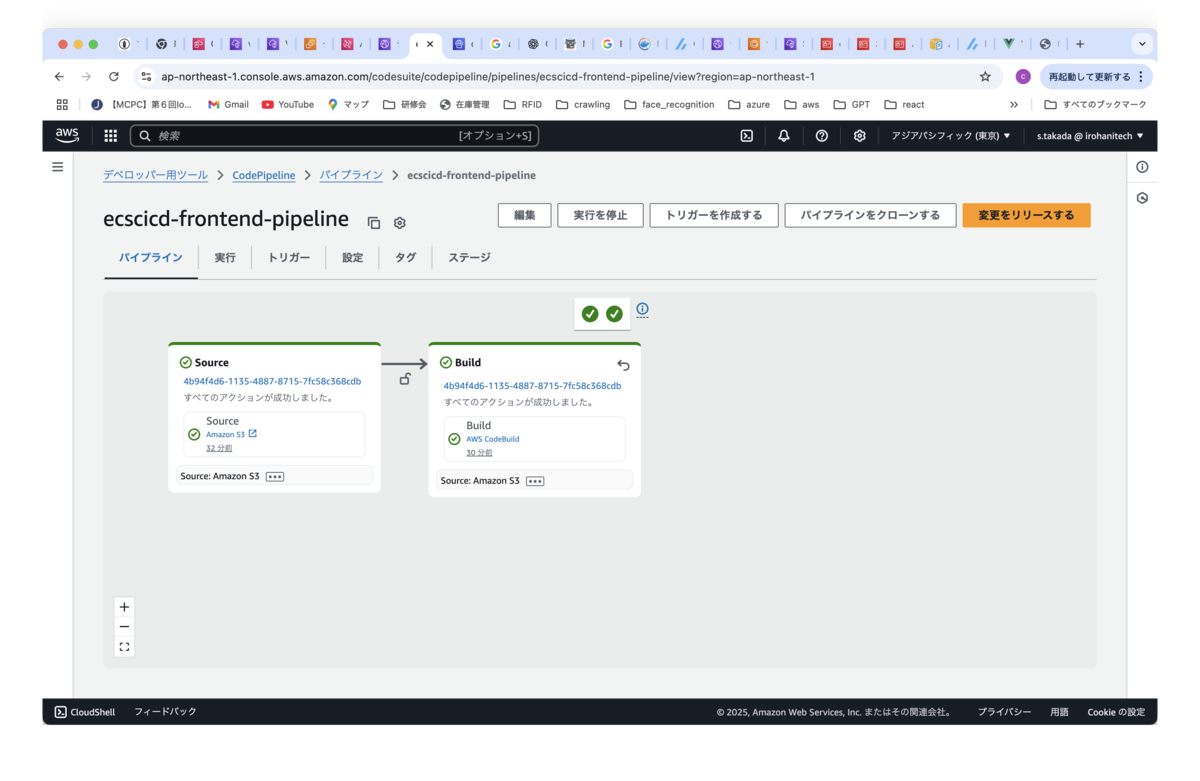
バックエンドのパイプラインは、デプロイアクションで一旦、「進行中」のまま停止状態になります。

これは、ECSタスクのBlue/Greenデプロイに伴う確認時間(ベイクタイム)であり、動作確認を実施した上で、CodeDeploy画面でタスクを終了させる必要があります。
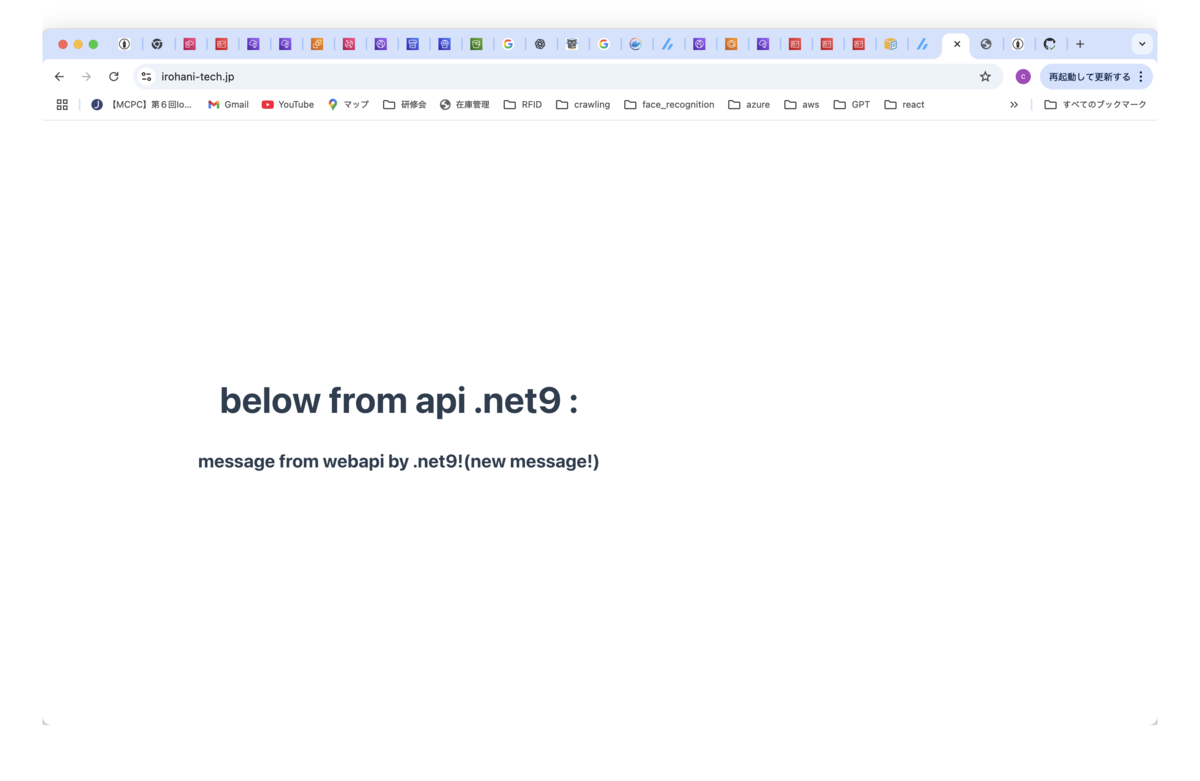
確認方法は、ブラウザからALBのDNSに対してテストポート(8080)でアクセスします。画面に表示された内容は、GreenのAPI(修正後)が返却した内容です。今回は初回デプロイのため、初期メッセージと同じものが出力されていますが、実際のリリースでは修正後にGitにプッシュしたメッセージが表示されます。

APIの返却が正しいことを確認したら、CodeDeployサービスの画面を開きます。画面右上の「トラフィックの再ルーティング」ボタンをクリックすることで、GreenがBlueに置き換わり、本番のリクエストが新環境にルーティングされるようになります。

最後に、「元のタスクセットの終了」をクリックします。これにより、旧ソースの呼び出しルートが削除されます。

GitHubとのOIDC連携
最後の手順として、GitHubへのプッシュをトリガーに、GitHub Actionsがソース格納先バケットにソースのzipファイルを格納する連携部分を構築します。

GitHub ActionsがAWSにアクセスするために、IAMロールでOIDCプロバイダを構築して、そのロールをGitHubのシークレットに設定します。
まずはOIDCプロバイダを作成するため、以下のコマンドでCloudFormationスタックを作成します。
# 9.oidc_from_github aws cloudformation create-stack --stack-name ecscicd-oidc \ --template-body file://template/9.oidc_from_github.yaml \ --capabilities CAPABILITY_NAMED_IAM \ --region ap-northeast-1 \ --parameters file://parameter/parameter_oidc.json
これにより、IAMのIDプロバイダにOIDC向けのプロバイダが作成されます。

さらに、IAMロールとして上記のプロバイダを信頼関係としたロールが作成されます。

このロールを、GitHubのシークレットに設定し、GitHub Actionsを起動できるようにします。この手順については、別途以下の記事に記載していますので、そちらをご参照ください。
上記の設定を行うことで、本ソースの .github/workflow/ に定義した、フロント、バックエンドそれぞれに対するGitHub Actions定義に従い、ワークフローが実行されます。

GitHub連携 動作確認
ソースを修正して、GitHubにプッシュを実行します。今回は、バックエンドの応答メッセージを少し変更してプッシュしました。
プッシュをトリガーに、GitHubのActionsワークフローが実行され、S3バケットにbackend.zip をアップロードします。

S3バケットでは、ファイルが更新されたことが確認できます。

S3バケットのファイル更新をトリガーに、Code pipelineが実行され、ECSタスクが更新されます。

更新を確定した後、Webページを再度参照すると、メッセージが更新されていることが確認できます(更新されない場合は、CloudFrontのキャッシュ削除を実行してみてください)
以上が、ECSサービスを使用したWebサイトのCI/CDデプロイとなります。
まとめ
いくつか残課題があるので、以下に示しておきます。
- CloudFrontのキャッシュ削除は、フロント・バック両方のパイプラインで共通的に実行すべき。
- 外部からALBへのアクセス経路が残っている。S3サイトからしかアクセスできないよう、制限を加えるべき。
- 本投稿の少し前(2025/07/17頃)、ECSネイティブのBlue/GreenデプロイがGAされた 。今後は、こちらが推奨手順となるため、そちらに切り替える。ただし、現時点でCodePipelineとの組み合わせ情報が少ないため、別途手順調査中。
ノートPC修理 電源ケーブル接触不良
知人にあげたPCが壊れたみたいで、ヘルプの連絡が来ました。
PCと電源ケーブル繋がってる状態で、PCをちょっと高いところから落としてしまいました。 PCは普通に起動するんだけども、電源ケーブル刺しても充電されなくなってしまいました・・・。 落とした直後、PCの電源ケーブルの差込口のケースが少し外れかかっていたので、えい、と押したら、ケースは直ったんだけども。。。 PCの電源ケーブルの差込口付近の故障か、電源ケーブル側の故障か、わからない状態だけども、これって見れます? 難しそうだったらどっか修理店探します。ごめんなさい。
あとで聞いた話によると、お子さんが暴れて机の上にあったノートPCをケーブルごとおっことしたらしい。あるある。
筐体は、東芝のDynabook。2018年のものなので、少し古いんだけど。
dynabook AZ65/FG PAZ65FG-BEM 15.6型フルHD Core i7 8550U

修理開始
初見
PC自体は残っていたバッテリで動くのだけど、電源アダプタをさしてみても、充電ランプの反応なし。
安定化電源で接続してみたけど、うんともすんとも言わないので、給電自体ができていないということはわかりました。
裏蓋を開ける
今回一番苦労したのがここ。裏蓋を抑えているネジの軸受けが壊れたのか、ネジが空回りして蓋を開けられない。しかも4箇所。
仕方ないので、蓋の隙間にマイナスドライバを突っ込んで少し力づくで押し上げながら、ネジをぐりぐりしたところ、なんとかネジを取り出せました。20分ほどかかりました。
端子確認
電源は左上の挿し口から、端子を通してマザーボードに給電されています。

アップの画像はこちら。

この端子が断線している可能性を考えて、ケーブルだけを取り外してみたところ、ソケットが抜けていることが判明。
 通常、このソケットはあまり抜けないようになっているのだけど、衝撃のためか、押さえ部分が緩くなっていた様子でした。
通常、このソケットはあまり抜けないようになっているのだけど、衝撃のためか、押さえ部分が緩くなっていた様子でした。
念の為、テスターを使って、ケーブル自体の給電状況をチェックしましたが、問題なく19Vきているので、ケーブル自体には問題なし。

ひとまず、ソケットを手で差し込み直した状態で、電源を繋いでみたところ、無事充電されることがわかりました。

処置
応急処置として、ソケットから端子が抜けないように、ボンドで補強しました。

端子をボードに接続し直した後、各部を組み直してACアダプタを接続。

無事、充電が開始され、PCの方でも接続を認識してくれました。
衝撃でカバーがボロボロに。。。
PC背面のネジ受けがいくつか割れてしまっていて、一部ネジがとまらない状態になってしまっていました。

内部にもプラスチックの破損が残留している状態だったので、除去。結構傷んだみたいですが、動作自体には支障なしでした。

まとめ
今回は2時間程度と、割と簡単に対応できました。
良かった良かった。
TerraformでAWS IaC実践 第3回 Terraformでネットワークを構築
前回からだいぶ空いてしまいましたが、今回はTerraformを使用して、以前作成したネットワーク構成を作成します。 Terraformの基礎については、前回までの記事を参照ください。
ネットワーク構成図
今回は、以下の構成のネットワークを作成します。
 非常にシンプルなSubnet、EC2構造です。ALBなどの負荷分散構成は機会があればまた今度。
ちなみに、過去のブログで同じ構造をCloudFormationで作成しています。そちらを知りたい方は、このリンクをクリックしてください。
非常にシンプルなSubnet、EC2構造です。ALBなどの負荷分散構成は機会があればまた今度。
ちなみに、過去のブログで同じ構造をCloudFormationで作成しています。そちらを知りたい方は、このリンクをクリックしてください。
構築手順
Terraformファイル入手/編集
上図のTerraformリソースは、以下のGitに格納していますので、そちらからCloneしてください。
クローンされたファイルの概要は以下の通りです。
| ファイル名 | 定義内容 |
|---|---|
| main.tf | provider(AWS)と、backend管理場所(後述)を定義 |
| variables.tf | tf全体で使用する変数を定義 |
| network.tf | VPC、Subnet、IGW、RouteTable、NAT、ElasticIPを定義 |
| server.tf | EC2、SecurityGroupを2組定義(Public / Private) |
| keypair.tf | EC2に使用するKeyPairを定義 |
クローンしたファイルのうち、次のファイル内容を編集します。
main.tf
provider "aws" { region = var.region } terraform { backend "s3" { region = "ap-northeast-1" bucket = "tf-tutorial-infra" key = "tf-tutorial.tfstate" } }
上記のterraform.backendでは、Terraformのtfstateファイルの管理場所を指定しています。tfstateは、Terraformでは構成されたリソースの一覧(CFnで言うスタック)情報に該当します。今回のTFでは、S3で管理することとしています。
bucket =に、自身のAWS環境のS3 Bucketを設定してください。バケットがない場合は、S3にバケットを新規作成して、そのバケット名を設定してください。設定後、保存しましょう。
事前準備
AWS CLIを使用するには、AWSのアカウントを作成の上で、次の準備が必要となります。
- AWS CLIをローカル環境にインストールする。
- AWSコンソールで IAM サービスを開き、CLIを使用するアカウントとアクセスキーを作成する
- ローカル環境でコマンドプロンプトから
aws configureをコマンドを実行し、リージョン・アクセスキーを設定する。
ここでは詳細は割愛します。↓の公式ページを参照ください。
terraformで環境をデプロイ
terraform init
Cloneしたディレクトリに移動して、terraform initコマンドを実行します。
実行に成功すると、S3がBackendに設定されるとともに、main.tfで定義したprovider "AWS"の記述に従って、必要なプロバイダがダウンロードされ、Terraform環境が初期化されます。
$ terraform init Initializing the backend... Successfully configured the backend "s3"! Terraform will automatically use this backend unless the backend configuration changes. Initializing provider plugins... - Reusing previous version of hashicorp/aws from the dependency lock file - Reusing previous version of hashicorp/tls from the dependency lock file - Reusing previous version of hashicorp/local from the dependency lock file - Installing hashicorp/aws v5.57.0... - Installed hashicorp/aws v5.57.0 (signed by HashiCorp) - Installing hashicorp/tls v4.0.5... - Installed hashicorp/tls v4.0.5 (signed by HashiCorp) - Installing hashicorp/local v2.5.1... - Installed hashicorp/local v2.5.1 (signed by HashiCorp) Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.
terraform plan
次にterraform planコマンドを実行し、Tfファイルのチェックと、作成されるリソースの確認を行います。
実行すると、直後に確認用のプロンプトが表示されます。
$ terraform plan var.tft_my_ipaddress_cidr (Required)Mapping to Inbound rule on ec2'security group. Enter a value:
この入力はvariables.tfファイルであらかじめ定義している必須パラメタの入力です。
ここでは、現在作業している自分のPCの、グローバルIPアドレスをCIDRで入力するよう、促しています。
入力したCIDRアドレスはパブリックEC2のセキュリティグループに、インバウンドの送信元IPアドレスとして適用されるよう、コーディングしてあります。
自分のグローバルIPアドレスがわからない場合は、WhatisMyIpAddressなどで確認できます。

ここで表示されるIPv4のアドレスを、CIDR表記(後ろに/32を付与)で入力します。
$ terraform plan var.tft_my_ipaddress_cidr (Required)Mapping to Inbound rule on ec2'security group. Enter a value: 60.111.xxx.yyy/32
Enterをクリックすると、AWS環境に構築する予定のリソースが画面に表示されます。
data.aws_ssm_parameter.amzn2_latest: Reading... data.aws_ssm_parameter.amzn2_latest: Read complete after 0s [id=/aws/service/ami-amazon-linux-latest/amzn2-ami-kernel-5.10-hvm-x86_64-gp2] Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_eip.tft_natgw_eip will be created + resource "aws_eip" "tft_natgw_eip" { + allocation_id = (known after apply) + arn = (known after apply) + association_id = (known after apply) + carrier_ip = (known after apply) + customer_owned_ip = (known after apply) + domain = "vpc" : : : # tls_private_key.keygen will be created + resource "tls_private_key" "keygen" { + algorithm = "RSA" + ecdsa_curve = "P224" + id = (known after apply) + private_key_openssh = (sensitive value) + private_key_pem = (sensitive value) + private_key_pem_pkcs8 = (sensitive value) + public_key_fingerprint_md5 = (known after apply) + public_key_fingerprint_sha256 = (known after apply) + public_key_openssh = (known after apply) + public_key_pem = (known after apply) + rsa_bits = 4096 } Plan: 24 to add, 0 to change, 0 to destroy. Changes to Outputs: + public_ip_address = (known after apply)
エラーが出なければ、ひとまずtfstate上では問題なく構成できることが確認できたことになります。
細かい説明は割愛しますが、全部で24のリソースが作られる見込みであることがわかります。
最後のpublic_ip_addressには、環境構築後、アクセス可能なパブリックEC2のIPアドレスが表示されます。
terraform apply
planで問題がなければ、改めてterraform planコマンドで実際に環境にデプロイを行います。
先ほどと同様に自身のIPアドレス入力を行った後、planと同様に作成リソースが表示されます。
最後に、以下のように実行確認が行われますので、yesと入力してください。
Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes
ターミナルが進行し、同時に各リソースがAWS上に作成されていきます。
tls_private_key.keygen: Creating... aws_eip.tft_natgw_eip: Creating... aws_vpc.tft_vpc: Creating... aws_eip.tft_natgw_eip: Creation complete after 1s [id=eipalloc-03bff180c7694d697] aws_vpc.tft_vpc: Creation complete after 1s [id=vpc-07667747badb175a9] aws_internet_gateway.tft_igw: Creating... aws_subnet.tft_private_subnet: Creating... aws_subnet.tft_public_subnet: Creating... aws_route_table.tft_private_rtb: Creating... aws_security_group.tft_private_ec2_sg: Creating... aws_route_table.tft_public_rtb: Creating... aws_security_group.tft_public_ec2_sg: Creating... : : : aws_nat_gateway.tft_natgw: Still creating... [2m0s elapsed] aws_nat_gateway.tft_natgw: Still creating... [2m10s elapsed] aws_nat_gateway.tft_natgw: Creation complete after 2m15s [id=nat-054f184171450366f] aws_route.tft_private_route: Creating... aws_route.tft_private_route: Creation complete after 1s [id=r-rtb-0d69b7febae3c87671080289494] Apply complete! Resources: 24 added, 0 changed, 0 destroyed. Outputs: public_ip_address = "13.231.xxx.yyy"
処理が終了し、最後にIPアドレスが表示されました。このIPアドレスが、パブリックEC2のグローバルIPアドレスとなります。
また、実行環境には「.key_pair」というディレクトリが追加されています。

この中には、EC2に接続するための秘密鍵(pem)と、EC2に格納された公開鍵(pub)が保存されています。これらは、次の接続確認で使用します。
接続確認
これにより、以下のネットワーク構成が作成されました。
<構成図(再掲)>
それでは、自端末からパブリックサブネットのEC2に接続確認を行ってみましょう。
接続は、以下のコマンドで実行します。最後のIPアドレスはapplyコマンドで最後に出力されたIPアドレスを指定します。
$ ssh -i ./.key_pair/tf-tutorial-ec2-key.id_rsa.pem ec2-user@13.231.xxx.yyy
以下のように表示されれば、接続成功です。

まとめ
以上で、Terraformを使用したAWS環境の構築について終わりたいと思います。
今回作った内容を見ても、24種類のリソースをコマンド一つで作れるというのが、やはり一番の魅力ですね。GUIでぽちぽちやることを考えても、効率面・品質面の両方でグッと楽になります。
今後は、よりクリティカルなノウハウについて(できるだけ早く)展開できればと思いますので、お待ちください。
TerraformでAWS IaC実践 第2回 HCL2構文基礎
今回は、記述言語であるHCL2の基礎と、Terraformファイルの概要についてアウトプットしていきます。環境構築等は前回のコラムを参照してください。
HCL2
HCL2(HashiCorp Language 2)言語とは
HCL(HashiCorp Configuration Language)2は、HashiCorpによって開発された設定言語の第二世代です。Terraformや他のHashiCorp製品で広く使用されている言語で、インフラストラクチャーの設定や管理を宣言的に記述するために設計されています。
<HCL2 例>
# ------------------------ # VPC # ------------------------ resource "aws_vpc" "vpc" { cidr_block = "192.168.0.0/20" instance_tenancy = "default" enable_dns_support = true enable_dns_hostnames = true assign_generated_ipv6_cidr_block = false # Tagづけ tags = { Name = "${var.project}-${var.environment}-vpc" Project = var.project Env = var.environment }
ブロック構造で記述されているため、パッと見はJSONに少し似ていますが、途中で # によるコメントを差し込めたりするなど、独自の構文となっています。
データ型
HCL2では、次のデータ型が使用できます。
| データ型 | 概要 |
|---|---|
| string | 文字列を表します。 |
| number | 数値を表します。 |
| bool | 真偽値(true/false)を表します。 |
| list | 配列やリストを表します。 |
| map | キーと値のペアのマップを表します。 |
| object | オブジェクトや構造体を表します。 |
| tuple | 固定長の要素を持つタプルを表します。 |
| set | 一意な値のセットを表します。 |
Terraformファイル
Terraformの管理ファイルには、主に以下のファイルが存在します。
- *.tfファイル:インフラリソース等の定義ファイル。ファイル内容はresource、data等、いくつかのブロックに分けて記述する(後述)
- terraform.tfvars:変数定義ファイル。Terraform全体で使用する変数を定義する。ファイル名は固定。
- terraform.tfstate:Terraformで生成されたリソースの状態管理ファイル。Terraform Applyによって固定のファイル名で自動生成される。
ディレクトリ構造については、現在も多くの議論が交わされているようですが、tfファイルはリソースごとに分離することは共通しているようです。
上記のうち、tfファイルについてご説明します。ファイル内容は、HCL2のテキスト形式で記述し、いくつかのブロックに分けて作成します。
ブロックタイプ
tfファイルは、ブロックと呼ばれる次の記述に分かれています。
| ブロックタイプ | 概要 |
|---|---|
| locals | 変数。外部から参照できないもの |
| variable | 変数。外部から参照できるもの |
| terraform | Terraformの設定 |
| provider | プロバイダ |
| data | Terraform管理していないリソースの取り込み |
| resource | Terraformの管理対象となるリソース |
| outputs | 外部から参照できるようにする値 |
ブロック詳細
locals
localsは、tfファイル内で使用するローカル変数を定義するものです。
# localsブロックで変数をKey = valueで定義する locals { env = "dev" } resource "aws_instance" "hello-world" { ami = "ami-04e0b6d6cfa432943" instance_type = "t2.micro" # 変数は ${local.変数名}で使用する tags = { Name = "HelloWorld" Env = "test-ec2-${local.env}" } }
variables
variablesは、localsと同様、変数を定義します。
定義した変数は、ファイルの外部から参照できます。
# 変数ごとにvariableブロックで変数を定義する # type にデータ型を指定する variable "env" { type = string default = "stg" } resource "aws_instance" "hello-world" { ami = "ami-04e0b6d6cfa432943" instance_type = "t2.micro" # 変数は ${var.変数名}で使用する tags = { Name = "HelloWorld" Env = "test-ec2-${var.env}" } }
上記で使用するデータ型には、以下のものが存在します。
- プリミティブ型
- string:Unicode文字列
- number:数値。整数と小数の両方を表現。
- bool:true/falseの2値
- 構造体
- object({<NAME=
, ...}):キーバリュー型データ - tuple([<TYPE], ...):各列の型が決まっている配列
- object({<NAME=
- コレクション
- list([TYPE]):特定の型で構成される配列
- map([TYPE]):キーが文字列の配列
- set([TYPE]):値の重複がない配列
変数 variablesは、以下に示すいくつかの方法で値を書き換えることができます。
OS環境変数で値を設定する。
変数ファイル
terraform.tfvarsで値を設定する。terraform.tfvars(ファイル名固定)を定義し、その中で値を設定します。terraform.tfvars
env = "debug"
terraformコマンドの引数
-var、-var-file [ファイル名]で値を設定するterraform applyコマンドの引数として値を設定します。実行コマンド
$ terraform apply -var env="test"
terraform
terraformブロックは、terraform自体の設定に関する値を指定します。代表的な例としては、required_versionでterraformの動作バージョン等を指定します。
# このtfファイルでは、terraform 1.8.2 以上のバージョンで動作することを定義 terraform { required_version = "~>1.8.2" }
また、Terraformのリソース状態を管理するファイルである .tfstateファイルを管理する場所を指定する場合は、backend をこちらに記述します。
# backendブロックで、tfstateをS3上に保存するよう指示 terraform { backend "s3" { bucket = "tfstate-bucket-camelrush" key = "dev.tfstate" region = "ap-northeast-1" profile = "terraform" } }
provider
providerには、Terraformで使用するプロバイダを指定します。ここには、Terraformが対応しているプロバイダリストの中から選択して指定します。今回はawsですが、azureやgoogleのほか、Oracle Cloudといった多くのプロバイダが公開されています。詳細は以下をご確認ください。
なお、awsプロバイダに指定できるパラメタはこちらを参照ください。
最低限の記述としては、AWSへのアクセス情報を設定します。
# ----------------------------- # Provider # ----------------------------- provider "aws" { profile = "terraform" region = "ap-northeast-1" }
access_keyやsecret_keyを指定する方法もありますが、セキュリティ上は非推奨であり、tfファイル管理もしづらくなりますので、ここはprofileを指定しましょう。
別途、AWS CLIのaws configure -profile xxxxx(xxxxxをprofile名と一致させる)を実行して、ローカルプロファイル名(上記の場合は terraform )にアクセスキー等を設定しておきます。
data
dataブロックは、少し特殊な使い方をします。こちらには、Terraform管理外のリソースを、tfファイル等で使用するためのデータ・リストとして取り込む役割があります。
管理外とは、具体的にはAWSプロバイダが提供するID情報などが挙げられます。
以下では、EC2インスタンスを作成するために使用するAMI(PCのイメージ)のIDを指定するため、AWSが提供するAMIのリストから、希望する「Amazon Linux2の最新イメージ」をdataとして取得し、それを元にEC2を作成しています。
# --- data block --- data "aws_ami" "app" { most_recent = true owners = ["self", "amazon"] # filter.valuesに*を入れて複数をピックアップしたリストを取得 # 前述の`most_recent=true`でリストから最新を取得 filter { name = "name" values = ["amzn2-ami-kernel-5.10-hvm-2.0.*.0-x86_64-gp2"] } } # --- resource block --- resource "aws_instance" "app_server" { # amiには、前述で定義したdataブロックのAMIのIDを指定 ami = data.aws_ami.app.id # 以下、省略 : : }
dataブロックに使用できる項目は、リファレンスの各サービス下にData Sources として書かれていますので、参照してください。
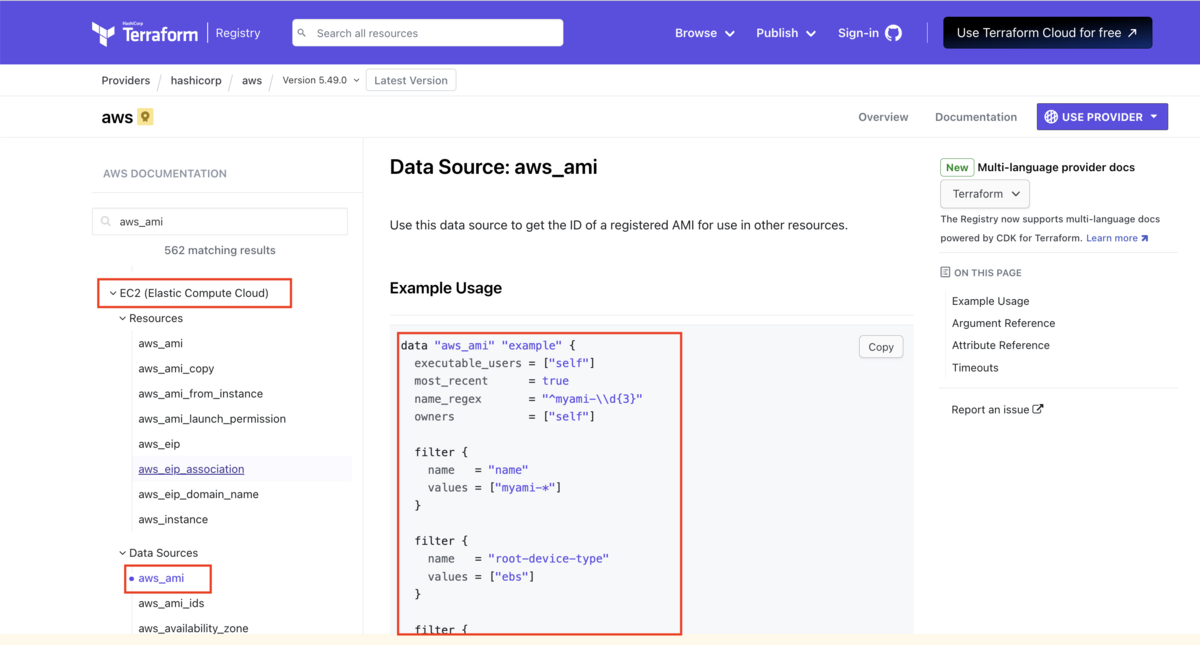
resource
resourceブロックには、Terraformで作成する各種サービスリソースを定義します。以下の様に記述します。
resource <リソース種類> <リソース名> { <各種パラメタ> }
以下に例を記述します。
# ------------------------ # VPC # ------------------------ resource "aws_vpc" "vpc" { cidr_block = "192.168.0.0/20" instance_tenancy = "default" enable_dns_support = true enable_dns_hostnames = true assign_generated_ipv6_cidr_block = false } # ------------------------ # Subnet # ------------------------ resource "aws_subnet" "public_subnet_1a" { vpc_id = aws_vpc.vpc.id availability_zone = "ap-northeast-1a" cidr_block = "192.168.1.0/24" map_public_ip_on_launch = true }
作成できるAWSリソースと、リソース種類別のパラメタについては、こちらのドキュメントを参照してください。
output
outputは、Terraformの設定間での明示的なデータ共有、状態の可視化、および外部ツールとの統合を容易にするために使用します。
<ec2.tf>
resource "aws_instance" "app_server" { ami = data.aws_ami.app.id : } # 自動で割り当てられたパブリックIPアドレスを出力 output "public_ip" { value = aws_instance.app_server.public_ip }
上記のように定義することで、Terraformコマンドを行ったオペレータに対して、「状態が可視化」されます。
<terraform apply コマンド>
$ irohani-mba:terraform shinya.takada$ terraform apply -auto-approve random_string.db_password: Refreshing state... [id=gKCzffFsy6bmZDQl] aws_db_option_group.mysql_standalone_optiongroup: Refreshing state... [id=tastylog-dev-mysql-standalone-optiongroup] data.aws_prefix_list.s3_pl: Reading... : : Apply complete! Resources: 0 added, 0 changed, 0 destroyed. Outputs: public_ip = "54.249.38.103"
outputはリソース作成自体には、影響を与えません。Terraformは、実行フォルダ配下のtfファイルを全て参照して依存関係を見つけるため、outputを記述しなくても、エラーにはなりません。
外部ツールとの統合では、CI/CDツールとの連携などにも活用されます。
Terraformのファイル構成
Terraformプロジェクトでは、いくつかの主要なファイルとディレクトリが使用されます。これらのファイルは、インフラストラクチャをコードとして管理する際に重要な役割を果たします。以下に、一般的なTerraformプロジェクトのファイル構成の例と、それぞれのファイルの役割を説明します。
一般的なディレクトリ構成
my-terraform-project/
├ main.tf
├ variables.tf
├ outputs.tf
├ terraform.tfvars
├ terraform.tfstate
├ terraform.tfstate.backup
├ .terraform/
├ modules/
└ example_module/
├ main.tf
├ variables.tf
└ outputs.tf
ファイルの説明
main.tf- Terraformの主要な設定ファイルで、リソースの定義やプロバイダーの設定が含まれます。
variables.tf- 変数の定義ファイルです。Terraformで使用する変数をここで宣言します。
outputs.tf- 出力値を定義するファイルです。Terraformが生成する値を他の場所で参照できるようにします。
terraform.tfvars- 変数の値を設定するファイルです。環境ごとに異なる設定を行う場合に使用します。
terraform.tfstate- Terraformの状態ファイルで、インフラストラクチャの現在の状態が記録されます。このファイルはTerraformによって自動的に管理されます。
terraform.tfstate.backup- 状態ファイルのバックアップです。変更を行う前の状態が保存されます。
.terraform/modules/- モジュールを保存するディレクトリです。再利用可能なTerraformコードをモジュールとしてまとめます。
モジュールの説明
モジュールは、Terraformのコードを再利用可能な単位にまとめたもので、プロジェクト全体の構造を整理しやすくします。例えば、上記の例では example_module というモジュールがあり、以下のファイルが含まれます。
modules/example_module/main.tf- モジュール内の主要な設定ファイルです。
modules/example_module/variables.tf- モジュール内で使用する変数を定義します。
modules/example_module/outputs.tf- モジュールの出力値を定義します。
このようなファイル構成を採用することで、Terraformプロジェクトを整理しやすくし、再利用性を高めることができます。
まとめ
少し長くなってしまいましたので、一旦解説はこの辺にして、次回は、terraformを使用したEC2ネットワークの構成を作っていきます。
TerraformでAWS IaC実践 第1回 Terraform基礎と環境構築
前回まで「CloudFormation」を使用したIaCを学んできましたが、今回からは別のIaCツールである「Terraform」を学習していきます。
Terraform基礎
Terraformは、HashiCorp社によって開発されたオープンソースのIaCツールです。大きな特徴として、AWSに限らず、Azure、GCP、Azureなど、マルチクラウドで使用できることが挙げられます。このことから、AWS専用のIaCである CloudFormationに比べて汎用性があります。
また記述言語は「HCL2(HashiCorp Language 2)」という独自言語となっています。JSONに似て非なるものであり、コメント文や、制御処理等の記述も行えます。
現時点でAWSに対するIaCツールといえば、CloudFormationか、Terraformの二択が代表的なものとなっています。
環境構築
tfenv + Terraform インストール
Terraformはバージョンによって挙動が異なるため、Terraformの仮想実行環境である tfenvをインストールし、その上にTerraformをインストールしていきます。
具体的なインストール手順は割愛しますので、後述のサイトを参照してください。
なお、Windowsの場合、tfenvがLinuxしかサポートしていないため、WSL2の実行環境を構築し、その上でtfenv、Terraformをインストールする手順となります。
<インストール参考(Windowsの場合)>
<インストール参考(Macの場合)>
なお、実行環境がApple silicon Mac(M1等)の場合、tfenv install コマンド実行時にエラーとなる場合があります。
このような場合は、以下のコマンドに振り替えてください。
# m1 mac ではエラーとなるため、以下の通り入力 $ TFENV_ARCH=amd64 tfenv install 1.8.2 Installing Terraform v1.8.2 Downloading release tarball from : : Installation of terraform v1.8.2 successful. To make this your default version, run 'tfenv use 1.8.2'
Terraformのインストールが完了したら、tfenv useコマンドで使用するTerraformのバージョンを指定して、環境を確定させます。
$ tfenv use 1.8.2 # versionは任意
AWS CLI 環境構築
ローカル環境のTerraformからAWSリソースを操作するには、AWS CLI環境を構築し、AWS IAMユーザのアクセスキーとシークレットアクセスキーを使用して、AWSにアクセスします。
詳細な説明は割愛しますが、次の作業を進めてください。
-
- 公式サイトに従ってインストールを行なってください。
IAMユーザの作成
- AWSマネージメントコンソールから、IAMユーザを新規に作成します。
- このユーザには、AdministratorAccessポリシーを適用します。
アクセスキー、シークレットアクセスキーの払い出し
CLI環境へのキー設定、profile作成
- 以下のコマンドで、CLIのプロファイルを作成します。なお、profile名の
terra-userは任意の名前で良いですが、後で使用しますので控えておいてください。
- 以下のコマンドで、CLIのプロファイルを作成します。なお、profile名の
$ aws configure --profile terra-user AWS Access Key ID [None]: ************* # 手順3のアクセスキーを入力 AWS Secret Access Key [None]: ************* # 手順3のシークレットアクセスキーを入力 Default region name [None]: ap-northeast-1 Default output format [None]: json
Terraformの実行
それでは実際にTerraformを動かして、DefaultVPC上にEC2を一台構築してみます(細かい構文説明は、次回以降で行うたため、今回は省きます)
tfファイルの作成
任意のフォルダに移動して、次のファイルを作成してください。
< main.tf > ※拡張子がtfであれば、ファイル名は任意で構いません
provider "aws" { profile = "terra-user" # 前述 aws configureのprofile名を指定 region = "ap-northeast-1" } # EC2をリソースに加える resource "aws_instance" "test-instance" { ami = "ami-0d0150aa305b7226d" instance_type = "t2.micro" }
amiに指定している値は、AWS EC2でAmazon Linux 2として使用できるマシンイメージのイメージIDを指定してください。

Terraformの実行
Terraformには、下表に示すように、いくつかの実行コマンドがあります。
| コマンド | 概要 |
|---|---|
terraform init |
Terraformの初期化とプラグインのインストールを行います。 |
terraform plan |
変更のプレビューを提供します。 |
terraform apply |
定義されたインフラストラクチャを構築または変更します。 |
terraform destroy |
Terraformによって管理されるインフラを破壊します。 |
terraform validate |
設定ファイルが正しいかどうかを検証します。 |
terraform refresh |
状態ファイルを実際のリソース状態に同期します。 |
terraform output |
出力変数の値を表示します。 |
terraform fmt |
設定ファイルを適切な形式に整形します。 |
一つ一つの説明は割愛しますが、ここでは次の手順でTerraformを実行し、AWSに対してmain.tfの内容を反映させます。
<main.tfをデプロイする>
# 初期化とプラグインのインストール $ terraform init # デプロイ(ユーザ確認なし) $ terraform apply -auto-approve
実行した結果を、AWSマネージメントコンソールのEC2画面で確認してください。
以下の画面写真のとおり、EC2が構築されていればOKです。

ところでこの時、コマンドを実行したパスに「.tfstate」というファイルが作られることに注目してください。このファイルには、applyコマンドによってAWSにデプロイされたリソース環境が記されています。
<terraform.tfstate>

Terraformではこのtfstateファイルによって、記述したtfファイルと実際の環境の差分を管理しています。
CloudFormationでは、このステータス管理がAWS内でフルマネージドで行われていたのに対し、Terraformでは外部ファイルで管理されています。このtfstateファイルがTerraform運用の一つの課題であるようです。アンマネージドなため、ファイル維持が必要だったり、複数エンジニア間で競合しないような施策が必要だったり。実際にはS3バケットで管理するといった運用方法もあるようですが、この辺りは今後も勉強していく必要がありそうです。
さて、EC2の確認できたら、以下のコマンドを実行してください。構築したEC2が削除されます。
<構築したEC2を破棄する>
# 構築したリソースの削除 $ terraform destroy -auto-approve
まとめ
今回は、簡単なtfファイルの定義でTerraformを動かし、EC2が構築できるところまで確認しました。言語仕様は違いますが、一度CloudFormationでIaCを実践していたため、それほど理解は難しくありませんでした。
次回から、HCL2の文法基礎を挟み、以前のCloudFormationで構築したのと同様の環境構築を行なっていく予定です。

余談ですが、 vscodeやcursorでtfファイルを記述する際には、Hashicorp TerraformのExtentionを追加しておくと、リソース名などをリストアップしてくれるので記述が楽になります。
AWS CloudFormation 実践 第5回 ChatGPTでコードレビュー
GitHub ActionsのMarketplaceを見ていたところ、気になるものがありました。
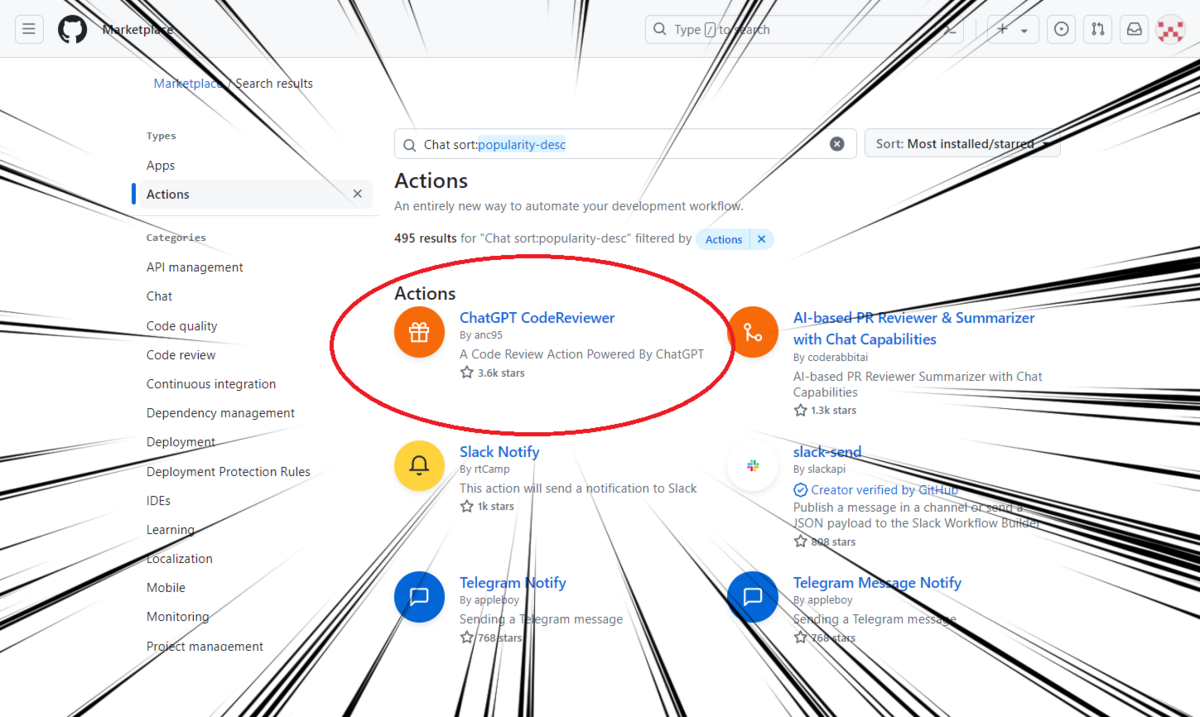
なんと「AIがコードレビューしてくれる」です。
今回はこちらについて、CI/CDを絡めた実装方法の手順説明と、実施結果の評価をやっていきたいと思います。
Cloud Formationから、やや脱線気味ですが・・・w
前提条件
構造としては、Gitでプルリクに対してChatGPTにレビューを行ってもらい、結果をレビューコメントとして、受け取ります(図の上部)これにより、メインブランチへのマージ前に、コード誤り・改善の気づきを得ることができます。
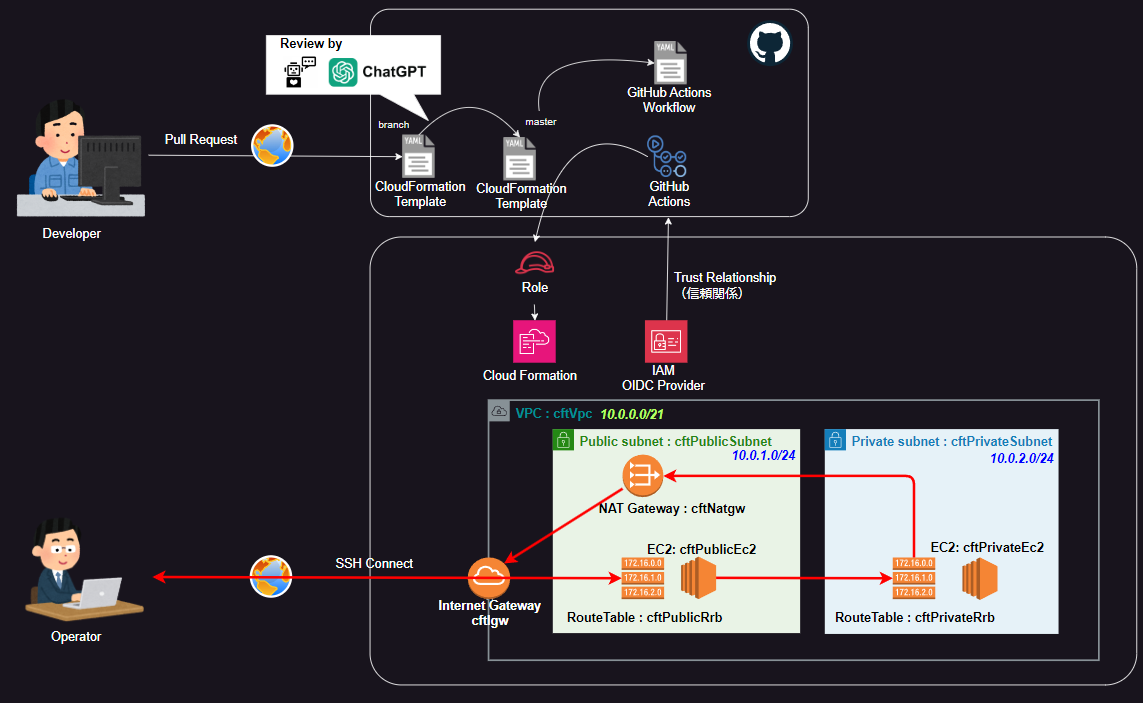
- 補足
- このActionsでは、ChatGPTのエンジンとして「ChatGPT 3.5」「4」「4 Turbo」等を指定できます。
- このレビュー機能は3.5でも使用可能ですが、上位バージョンを使用することで、レビュー精度は高くなります。
- 現在、4以降を使用するには、有償クレジットの購入(最低 5$)等が必要となります。
実装方法解説
GitHub Actionsワークフローに関する実装要素の細かいところなどは、前回の記事を参照ください。
GitHub Actionsのstepで、「anc95/ChatGPT-CodeReview@main」を使用します。
1. ChatGPTのAPI KEYを取得
高度なレビューを行いたい場合は、Credit(最低5$)を購入することで、使用可能となります。注意点を以下に挙げます。
2. GitHubレポジトリにAPI KEYを設定
- GitHubで、レビューするコードのレポジトリを開き、サインインします。
- 上部の「Settings」メニューを開き、サイドメニューから「Secrets and variables」-「Actions」を選択します。
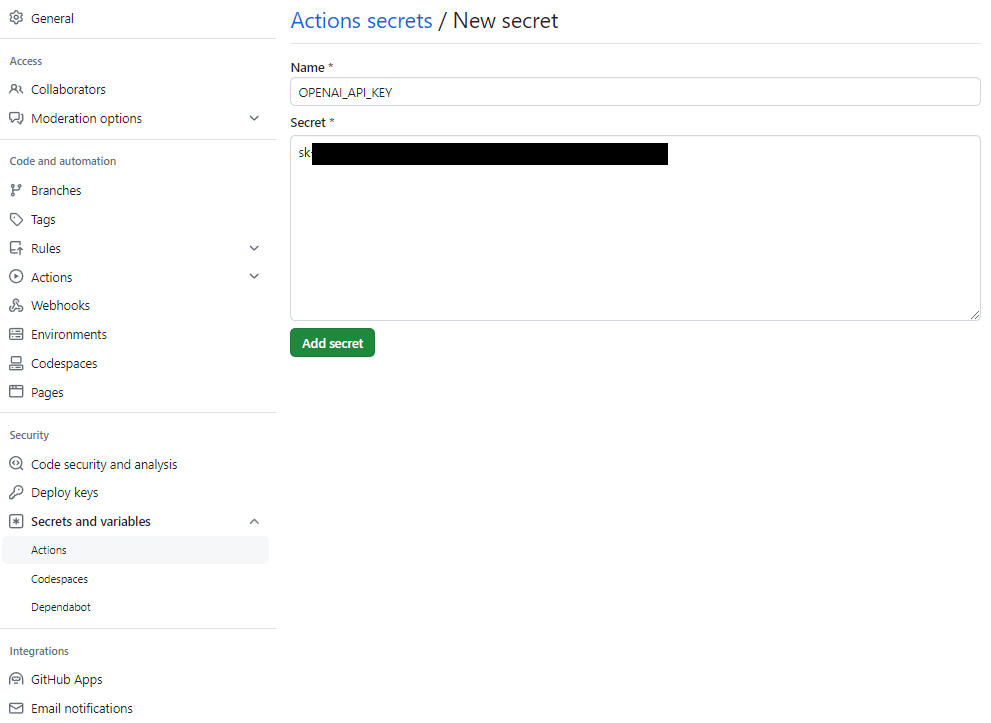
- 「New repository secret」ボタンをクリックします。
- 「Name」に「OPENAI_API_KEY」、「Secret」に取得したAPI KEYを設定して「Add secret」ボタンをクリックします。
3. Actionsワークフローを作成
- 対象のレポジトリに対し、ルート下にワークフローファイルを追加します(ファイルの作り方は、前回のコラムを参考にしてください)
- 作成するワークフローyamlは、次のとおりです(ほぼ、公式のサンプルのままです)
name: Code Review permissions: contents: read pull-requests: write on: pull_request: types: [opened, reopened, synchronize] jobs: review: # if: ${{ contains(github.event.*.labels.*.name, 'gpt review') }} # Optional; to run only when a label is attached runs-on: ubuntu-latest steps: - uses: anc95/ChatGPT-CodeReview@main env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }} # Optional LANGUAGE: Japanese OPENAI_API_ENDPOINT: https://api.openai.com/v1 MODEL: gpt-3.5-turbo # https://platform.openai.com/docs/models PROMPT: # example: Please check if there are any confusions or irregularities in the following code diff: top_p: 1 # https://platform.openai.com/docs/api-reference/chat/create#chat/create-top_p temperature: 1 # https://platform.openai.com/docs/api-reference/chat/create#chat/create-temperature max_tokens: 4096 MAX_PATCH_LENGTH: 10000 # if the patch/diff length is large than MAX_PATCH_LENGTH, will be ignored and won't review. By default, with no MAX_PATCH_LENGTH set, there is also no limit for the patch/diff length.
on: pull_requestとあるとおり、このワークフローは、プルリクエストの操作時に実行されます。MODEL: gpt-3.5-turboの部分が、レビューエンジンの指定です。高度なAIを使用されたい方は、gpt-4-turboに変更してください(ただし、こちらを使用するには、前述のとおり、最低 5$のCredit購入が必要です)max_tokens: 4096は、無償版を想定した場合の最大値です。有償版であればもっと大きい値が指定可能です。- 作成したワークフローファイルを、Master(Main)ブランチにCommit、Pushします。
4. レビュー依頼(Pull Request)を作成
- レビューして欲しいコードを、ワークブランチにPushします。
- レビューは、Pull Requestが示す変更の差分に対してだけ行われます。そのため、ソース全部をレビューさせるには、一旦ソースファイル自体をレポジトリから削除して、再度ファイルをPushしなおした方がよいです。
- GitHubのPull Requestメニューから、「New pull request」ボタンをクリックします。
- 上部でMaster(main)ブランチへのマージを指定して、「Create pull request」ボタンを押します。

- 次画面で「Create pull request」ボタンを押すと、ワークフローが開始されます。
コードレビューが終わると、プルリクへのコメントとしてレビュー結果が応答されます(メールでも配信されてきました)
以上が実施手順となります。
それではやってみましょう!
レビューのお題
レビュー対象は、前回までのCloud Formationテンプレートファイルとしました。
内容を、以下に再掲します。
▼(テンプレート全文はここをクリックしてください)
AWSTemplateFormatVersion: 2010-09-09 Parameters: # My IP Address CIDR(Required) cftMyIpAddressCidr: Type: String Description: (Required)Mapping to Inbound rule on ec2'security group. # Environment variable cftEnv: Type: String Default: Dev AllowedValues: - Prd - Stg - Dev Description: Enter Environment Prd, Stg or Dev. Default is Dev. Mappings: # Environment Mapping cftEnvMap: Prd: Suffix: prd InstanceType: t3.small VpcCidr: 10.2.0.0/21 PublicSubnetCidr: 10.2.1.0/24 PrivateSubnetCidr: 10.2.2.0/24 Stg: Suffix: stg InstanceType: t3.small VpcCidr: 10.1.0.0/21 PublicSubnetCidr: 10.1.1.0/24 PrivateSubnetCidr: 10.1.2.0/24 Dev: Suffix: dev InstanceType: t3.micro VpcCidr: 10.0.0.0/21 PublicSubnetCidr: 10.0.1.0/24 PrivateSubnetCidr: 10.0.2.0/24 Resources: # VPC cftVpc: Type: AWS::EC2::VPC Properties: CidrBlock: !FindInMap [cftEnvMap, !Ref cftEnv, VpcCidr] EnableDnsSupport: true Tags: - Key: Name Value: !Sub - cf-tutorial-vpc-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} # Internet Gateway cftIgw: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: !Sub - cf-tutorial-igw-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix]} AttachGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref cftVpc InternetGatewayId: !Ref cftIgw # Subnet (public) cftPublicSubnet: Type: AWS::EC2::Subnet Properties: AvailabilityZone: ap-northeast-1a MapPublicIpOnLaunch: true VpcId: !Ref cftVpc CidrBlock: !FindInMap [cftEnvMap, !Ref cftEnv, PublicSubnetCidr] Tags: - Key: Name Value: !Sub - cf-tutorial-public-subnet-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} cftPublicRtb: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref cftVpc Tags: - Key: Name Value: !Sub - cf-tutorial-public-rtb-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} cftPublicRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref cftPublicRtb DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref cftIgw cftPublicRtAssoc: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref cftPublicSubnet RouteTableId: !Ref cftPublicRtb # Subnet (private) cftPrivateSubnet: Type: AWS::EC2::Subnet Properties: AvailabilityZone: ap-northeast-1a MapPublicIpOnLaunch: false VpcId: !Ref cftVpc CidrBlock: !FindInMap [cftEnvMap, !Ref cftEnv, PrivateSubnetCidr] Tags: - Key: Name Value: !Sub - cf-tutorial-private-subnet-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} cftPrivateRtb: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref cftVpc Tags: - Key: Name Value: !Sub - cf-tutorial-private-rtb-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} cftPrivateRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref cftPrivateRtb DestinationCidrBlock: 0.0.0.0/0 NatGatewayId: !Ref cftNatgw cftPrivateRtAssoc: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref cftPrivateSubnet RouteTableId: !Ref cftPrivateRtb # NAT Gateway cftNatgw: Type: AWS::EC2::NatGateway Properties: AllocationId: !GetAtt cftNatgwEip.AllocationId SubnetId: !Ref cftPublicSubnet Tags: - Key: Name Value: !Sub - cf-tutorial-natgw-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} cftNatgwEip: Type: AWS::EC2::EIP Properties: Domain: vpc # EC2(public) cftPublicEc2: Type: AWS::EC2::Instance Properties: KeyName: cf-tutorial-ec2-key DisableApiTermination: false ImageId: ami-020283e959651b381 InstanceType: !FindInMap [cftEnvMap, !Ref cftEnv, InstanceType] SubnetId: !Ref cftPublicSubnet Monitoring: false SecurityGroupIds: - !Ref cftPublicEc2Sg UserData: !Base64 | #!/bin/bash -ex # put your script here Tags: - Key: Name Value: !Sub - cf-tutorial-public-ec2-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} # SecurityGroup(public EC2) cftPublicEc2Sg: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub - cf-tutorial-public-ec2-sg-${env} - {env: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix]} GroupDescription: Allow SSH Access. VpcId: !Ref cftVpc SecurityGroupIngress: - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: !Sub - ${MyIpCidr} - {MyIpCidr: !Ref cftMyIpAddressCidr} Tags: - Key: Name Value: !Sub - cf-tutorial-public-ec2-sg-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} # ElasicIp for public EC2 cftPublicEc2Eip: Type: AWS::EC2::EIP Properties: InstanceId: !Ref cftPublicEc2 # EC2(private) cftPrivateEc2: Type: AWS::EC2::Instance Properties: KeyName: cf-tutorial-ec2-key DisableApiTermination: false ImageId: ami-020283e959651b381 InstanceType: !FindInMap [cftEnvMap, !Ref cftEnv, InstanceType] SubnetId: !Ref cftPrivateSubnet Monitoring: false SecurityGroupIds: - !Ref cftPrivateEc2Sg UserData: !Base64 | #!/bin/bash -ex # put your script here Tags: - Key: Name Value: !Sub - cf-tutorial-private-ec2-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} # SecurityGroup(private EC2) cftPrivateEc2Sg: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub - cf-tutorial-private-ec2-sg-${env} - {env: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix]} GroupDescription: Allow SSH Access from Public EC2 Only. VpcId: !Ref cftVpc SecurityGroupIngress: - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: !Sub - ${privateIp}/32 - {privateIp: !GetAtt cftPublicEc2.PrivateIp} Tags: - Key: Name Value: !Sub - cf-tutorial-private-ec2-sg-${suffix} - {suffix: !FindInMap [cftEnvMap, !Ref cftEnv, Suffix],} # ====================== # Outputs Statement # ====================== # IP Address Allocated to Public EC2 Outputs: cftPublicEc2Eip: Value: !GetAtt cftPublicEc2Eip.PublicIp
実行結果
上記をAIでレビューしてもらった結果、次のとおり回答されました。

ChatGPTらしく、すごい精度で回答が出てきました。
いくつか、ピックアップしてみます。
- 「ポジティブな点」で、いくつかほめてくれててうれしい^^。「3. リソースタグ付け」は「タグ付けしているからわかりやすいね」だ。ふむふむ。
- 「2. EIPリソースの属性」は「宣言が上下逆だ」と言っている。問題はないので、不要な指摘っぽい。
- 「3. パラメータの検証」は「CIDR形式かどうかチェックが必要だ」と言っている。さらに、「セキュリティリスクになる可能性がある」と警告しており、Ingress記述と併せて、この指定がネットワークのエンドポイントになっていることが理解できているのがすごい!
- 「4. 可用性ゾーンのハードコーディング」は「AZを固定しているからParameterやMappingで指定するようにしては?」と言ってる。ごもっとも。
まとめ
今回、NGの指摘ポイントを作り忘れたので、明確なNG指摘はありませんでしたが、それでもこれだけ改善提案を出してくれるのはありがたいです。実際にレビューアに提出する前に指摘を上げてくれるので、本人の気づきにもなりますし、開発の運用効率も上がりますね。