最近話題になっているらしい、画像生成AIというものを使ってみたので、レポートします。
AI作「鮭を食べている熊が川辺にいるイラスト 油絵」 笑

鮭はどこ行ったんだろう・・・。
用意するもの
GPUを使うといっても、クラウドのサービスを活用して行うので、高スペックのPCなどは必要ありません。以下のものを準備してください。
Google colaboratory 環境
Googleが提供しているGPUクラウド環境(無料)です。Googleアカウントを持っていれば、誰でも使用ができます。こちらのサイトにアクセスしてください。
Hugging Faceアカウント
Hugging Faceは、主に自然言語処理に関連したライブラリの開発や人工知能のコミュニティを運営しているアメリカの企業。こちらのサイトにアクセスして、右上のSign Upを押してアカウントを作成してください。
手順
ライブラリのインストール
最初にブラウザを開き、Google colaboratoryにアクセスします。
ノートブックを新規作成したら、メニューから「ランタイム」-「ランタイムのタイプを変更」を選択します。

サブ画面が表示されるので「ハードウェア アクセラレータ」に「GPU」を選択して保存します。

次に別のブラウザページを開き、Hugging Faceにアクセスします。検索エリアに「japanese-stable-diffusion」と入力します。アクセスすると、下の画面が表示されます。

この画面をずーっと下まで進めると、「Examples」に、以下のインストールコマンド(pipコマンド)が書かれているので、これをコピーします。
!pip install git+https://github.com/rinnakk/japanese-stable-diffusion
上のコマンドを、Google colaboratoryのコード欄に貼り付けて実行します。貼り付ける時に、先頭に「!」を入力してください。これにより、環境にjapanese-stable-diffusionライブラリがインストールされます(少しかかった後、Success...と表示されたらOK)
HuggingFaceのアクセストークン取得・設定
Google colaboratory上部の「+コード」をクリックしてコード欄を追加し、ここに「!」に加えて、HugginFaceにCLIログインするためのコマンドを貼り付けて実行します。コマンドは、先ほど参照したHuggingFaceページの、pipコマンドのすぐ下にあります。
!huggingface-cli login
実行すると、以下の画面になりますので、画面内のハイパーリンクをクリックしてください。

リンク先に行くと、トークンの作成画面が表示されますので「New token」を押します。サブ画面で「Name(なんでも良い)」を登録して、「Generate Token」を押すと、トークンが表示されるので、そのままクリップボードにコピーしてください。
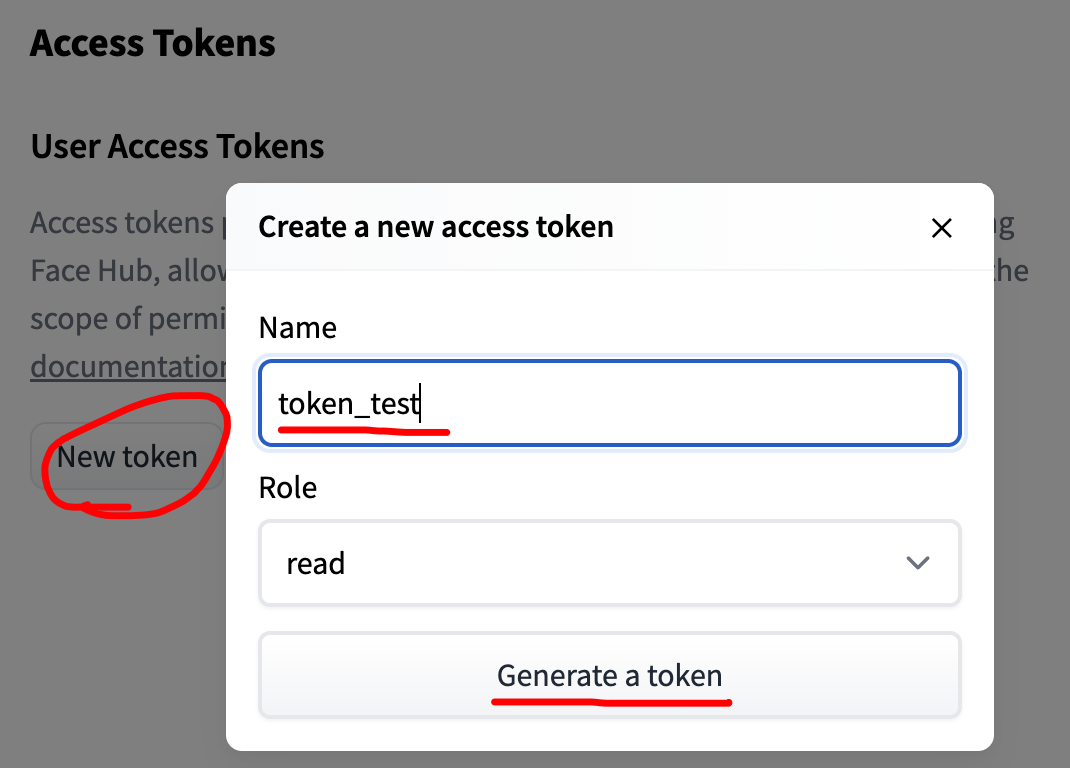
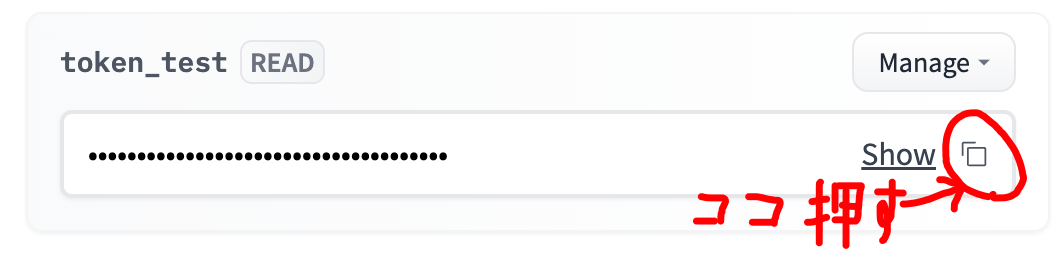
Google colaboratory画面に戻り「Token:」入力欄にトークンを貼り付けて実行してください。下のような画面になったらトークン設定は終了で、この後のpythonコードからHuggingFaceのサービスが使用できるようになります。

Pythonコードの実行
HuggingFaceのページ下部に、サンプルソースコードが表示されていますので、これをクリップボードにコピーして、Google colaboratoryのコード欄に貼り付けます。
import torch from torch import autocast from diffusers import LMSDiscreteScheduler from japanese_stable_diffusion import JapaneseStableDiffusionPipeline model_id = "rinna/japanese-stable-diffusion" device = "cuda" # Use the K-LMS scheduler here instead scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000) pipe = JapaneseStableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True) pipe = pipe.to(device) prompt = "猫の肖像画 油絵" with autocast("cuda"): image = pipe(prompt, guidance_scale=7.5).images[0] image.save("output.png")
最初に、一番下を以下のとおり変更してください。これにより、実行結果を画面上で確認することができるようになります。
:
# image.save("output.png")
image
あとは、コード内のprompt = "猫の肖像画 油絵"の部分を好きに書き換え得て、実行ボタンを押すだけです。最初は2〜3分ほどかかりますが、AIが適当な画像を自動生成して、画面に表示してくれます。
色々出してみた。
"京都の五重塔を遠くから撮影した写真 雪が降っている"

悪くないですね。降ってはいませんが、足元に雪が積もっているようです。
"オーロラを真上から見た映像, 鮮明な写真"

これは綺麗ですね。オーロラは、学習資料が色々あるんでしょうか。
"大都会のスクランブル交差点,たくさんの人がいる 油絵"

それっぽく描かれていますが、よく見ると人が崩れてしまっていて、正確に描けていませんね。
なお、日本語の指定にこだわらなければ、イラストに特化した描画エンジンを使用することもできます。以下のURLにアクセスして、サンプルソースを入手して、指定するワードを変更してみましょう。
"extermely detailed CG wallpaper, blonde hair, long hair, fantasy, pretty girl, slight smile, soft focus, beautiful composition, wearing armor"
(非常に詳細な CG の壁紙、ブロンドの髪、長い髪、ファンタジー、美少女、わずかな笑顔、ソフト フォーカス、美しい構図、鎧を着ています)

すごく綺麗に描かれました。
しばらく遊んでても飽きなそうですw